
轉(zhuǎn)載:http://www.cnblogs.com/haippy/archive/2011/12/10/2282943.html
1致性哈希算法在1997年由麻省理工學(xué)院的Karger等人在解決散布式Cache中提出的,設(shè)計(jì)目標(biāo)是為了解決因特網(wǎng)中的熱門(Hot spot)問題,初衷和CARP10分類似。1致性哈希修正了CARP使用的簡單哈希算法帶來的問題,使得DHT可以在P2P環(huán)境中真正得到利用。
但現(xiàn)在1致性hash算法在散布式系統(tǒng)中也得到了廣泛利用,研究過memcached緩存數(shù)據(jù)庫的人都知道,memcached服務(wù)器端本身不提供散布式cache的1致性,而是由客戶端來提供,具體在計(jì)算1致性hash時(shí)采取以下步驟:
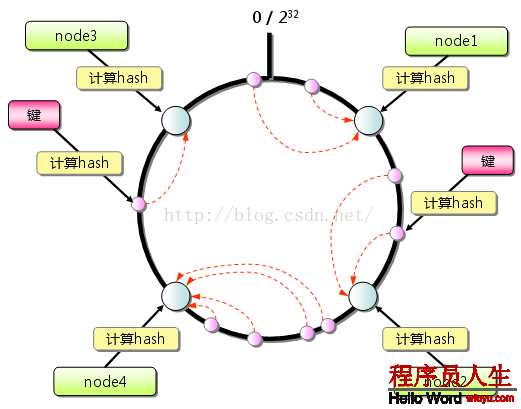
從上圖的狀態(tài)中添加1臺memcached服務(wù)器。余數(shù)散布式算法由于保存鍵的服務(wù)器會產(chǎn)生巨大變化而影響緩存的命中率,但Consistent Hashing中,只有在園(continuum)上增加服務(wù)器的地點(diǎn)逆時(shí)針方向的第1臺服務(wù)器上的鍵會遭到影響,以下圖所示:
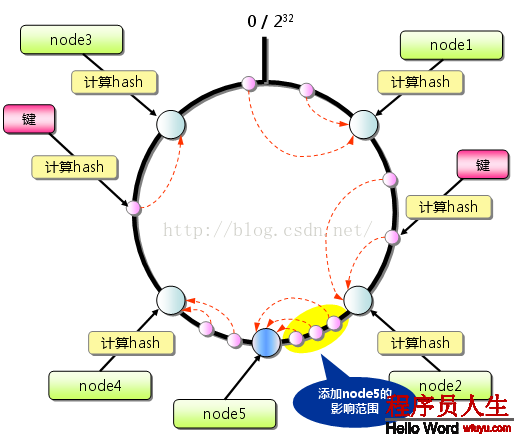
斟酌到散布式系統(tǒng)每一個(gè)節(jié)點(diǎn)都有可能失效,并且新的節(jié)點(diǎn)極可能動態(tài)的增加進(jìn)來,如何保證當(dāng)系統(tǒng)的節(jié)點(diǎn)數(shù)目產(chǎn)生變化時(shí)依然能夠?qū)ν馓峁┝己玫姆?wù),這是值得斟酌的,特別實(shí)在設(shè)計(jì)散布式緩存系統(tǒng)時(shí),如果某臺服務(wù)器失效,對全部系統(tǒng)來講如果不采取適合的算法來保證1致性,那末緩存于系統(tǒng)中的所有數(shù)據(jù)都可能會失效(即由于系統(tǒng)節(jié)點(diǎn)數(shù)目變少,客戶端在要求某1對象時(shí)需要重新計(jì)算其hash值(通常與系統(tǒng)中的節(jié)點(diǎn)數(shù)目有關(guān)),由于hash值已改變,所以極可能找不到保存該對象的服務(wù)器節(jié)點(diǎn)),因此1致性hash就顯得相當(dāng)重要,良好的散布式cahce系統(tǒng)中的1致性hash算法應(yīng)當(dāng)滿足以下幾個(gè)方面:
平衡性是指哈希的結(jié)果能夠盡量散布到所有的緩沖中去,這樣可使得所有的緩沖空間都得到利用。很多哈希算法都能夠滿足這1條件。
單調(diào)性是指如果已有1些內(nèi)容通過哈希分派到了相應(yīng)的緩沖中,又有新的緩沖區(qū)加入到系統(tǒng)中,那末哈希的結(jié)果應(yīng)能夠保證原有已分配的內(nèi)容可以被映照到新的緩沖區(qū)中去,而不會被映照到舊的緩沖集合中的其他緩沖區(qū)。簡單的哈希算法常常不能滿足單調(diào)性的要求,如最簡單的線性哈希:x = (ax + b) mod (P),在上式中,P表示全部緩沖的大小。不難看出,當(dāng)緩沖大小產(chǎn)生變化時(shí)(從P1到P2),原來所有的哈希結(jié)果均會產(chǎn)生變化,從而不滿足單調(diào)性的要求。哈希結(jié)果的變化意味著當(dāng)緩沖空間產(chǎn)生變化時(shí),所有的映照關(guān)系需要在系統(tǒng)內(nèi)全部更新。而在P2P系統(tǒng)內(nèi),緩沖的變化等價(jià)于Peer加入或退出系統(tǒng),這1情況在P2P系統(tǒng)中會頻繁產(chǎn)生,因此會帶來極大計(jì)算和傳輸負(fù)荷。單調(diào)性就是要求哈希算法能夠應(yīng)對這類情況。
在散布式環(huán)境中,終端有可能看不到所有的緩沖,而是只能看到其中的1部份。當(dāng)終端希望通過哈希進(jìn)程將內(nèi)容映照到緩沖上時(shí),由于不同終端所見的緩沖范圍有可能不同,從而致使哈希的結(jié)果不1致,終究的結(jié)果是相同的內(nèi)容被不同的終端映照到不同的緩沖區(qū)中。這類情況明顯是應(yīng)當(dāng)避免的,由于它致使相同內(nèi)容被存儲到不同緩沖中去,下降了系統(tǒng)存儲的效力。分散性的定義就是上述情況產(chǎn)生的嚴(yán)重程度。好的哈希算法應(yīng)能夠盡可能避免不1致的情況產(chǎn)生,也就是盡可能下降分散性。
負(fù)載問題實(shí)際上是從另外一個(gè)角度看待分散性問題。既然不同的終端可能將相同的內(nèi)容映照到不同的緩沖區(qū)中,那末對1個(gè)特定的緩沖區(qū)而言,也可能被不同的用戶映照為不同的內(nèi)容。與分散性1樣,這類情況也是應(yīng)當(dāng)避免的,因此好的哈希算法應(yīng)能夠盡可能下降緩沖的負(fù)荷。
平滑性是指緩存服務(wù)器的數(shù)目平滑改變和緩存對象的平滑改變是1致的。
1致性哈希算法(Consistent Hashing)最早在論文《Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web》中被提出。簡單來講,1致性哈希將全部哈希值空間組織成1個(gè)虛擬的圓環(huán),如假定某哈希函數(shù)H的值空間為0⑵^32⑴(即哈希值是1個(gè)32位無符號整形),全部哈希空間環(huán)以下:

全部空間按順時(shí)針方向組織。0和232⑴在零點(diǎn)中方向重合。
下1步將各個(gè)服務(wù)器使用Hash進(jìn)行1個(gè)哈希,具體可以選擇服務(wù)器的ip或主機(jī)名作為關(guān)鍵字進(jìn)行哈希,這樣每臺機(jī)器就可以肯定其在哈希環(huán)上的位置,這里假定將上文中4臺服務(wù)器使用ip地址哈希后在環(huán)空間的位置以下:
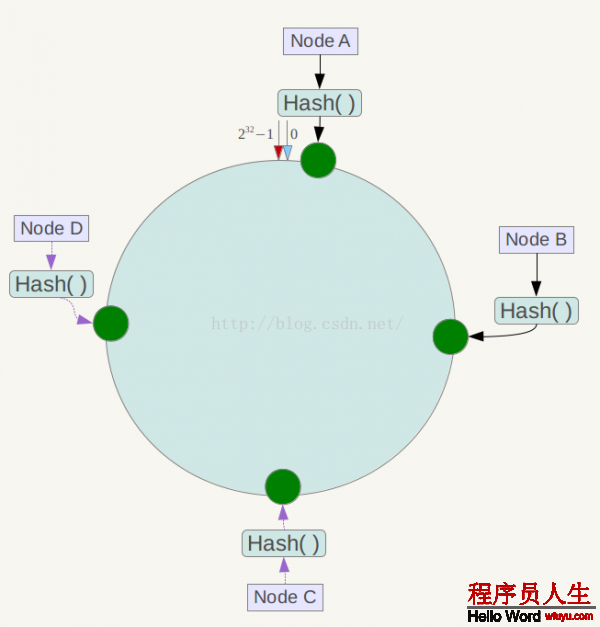
接下來使用以下算法定位數(shù)據(jù)訪問到相應(yīng)服務(wù)器:將數(shù)據(jù)key使用相同的函數(shù)Hash計(jì)算出哈希值,并肯定此數(shù)據(jù)在環(huán)上的位置,從此位置沿環(huán)順時(shí)針“行走”,第1臺遇到的服務(wù)器就是其應(yīng)當(dāng)定位到的服務(wù)器。
例如我們有Object A、Object B、Object C、Object D4個(gè)數(shù)據(jù)對象,經(jīng)過哈希計(jì)算后,在環(huán)空間上的位置以下:
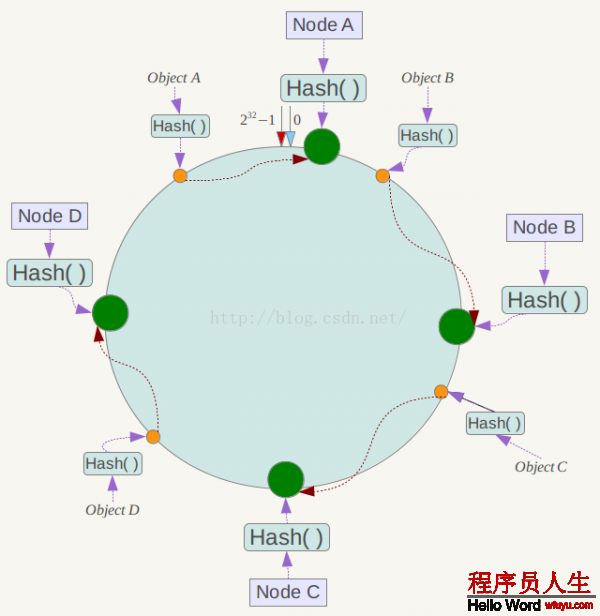
根據(jù)1致性哈希算法,數(shù)據(jù)A會被定為到Node A上,B被定為到Node B上,C被定為到Node C上,D被定為到Node D上。
下面分析1致性哈希算法的容錯性和可擴(kuò)大性。現(xiàn)假定Node C不幸宕機(jī),可以看到此時(shí)對象A、B、D不會遭到影響,只有C對象被重定位到Node D。1般的,在1致性哈希算法中,如果1臺服務(wù)器不可用,則受影響的數(shù)據(jù)僅僅是此服務(wù)器到其環(huán)空間中前1臺服務(wù)器(即沿著逆時(shí)針方向行走遇到的第1臺服務(wù)器)之間數(shù)據(jù),其它不會遭到影響。
下面斟酌另外1種情況,如果在系統(tǒng)中增加1臺服務(wù)器Node X,以下圖所示:
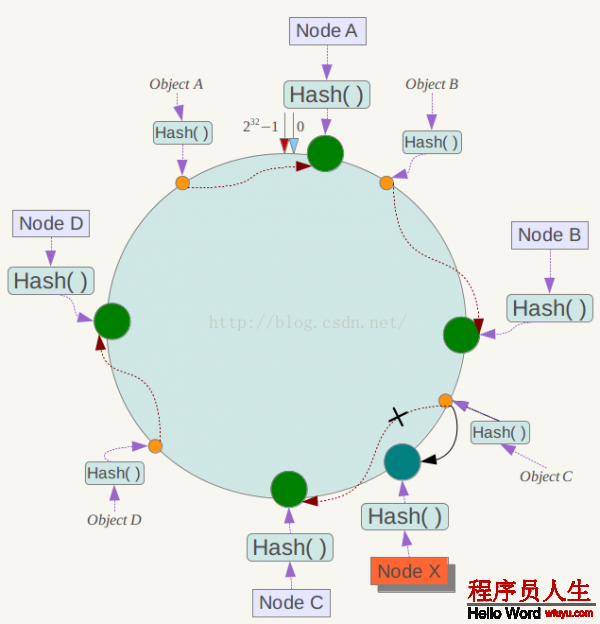
此時(shí)對象Object A、B、D不受影響,只有對象C需要重定位到新的Node X 。1般的,在1致性哈希算法中,如果增加1臺服務(wù)器,則受影響的數(shù)據(jù)僅僅是新服務(wù)器到其環(huán)空間中前1臺服務(wù)器(即沿著逆時(shí)針方向行走遇到的第1臺服務(wù)器)之間數(shù)據(jù),其它數(shù)據(jù)也不會遭到影響。
綜上所述,1致性哈希算法對節(jié)點(diǎn)的增減都只需重定位環(huán)空間中的1小部份數(shù)據(jù),具有較好的容錯性和可擴(kuò)大性。
另外,1致性哈希算法在服務(wù)節(jié)點(diǎn)太少時(shí),容易由于節(jié)點(diǎn)分部不均勻而造成數(shù)據(jù)傾斜問題。例如系統(tǒng)中只有兩臺服務(wù)器,其環(huán)散布以下,
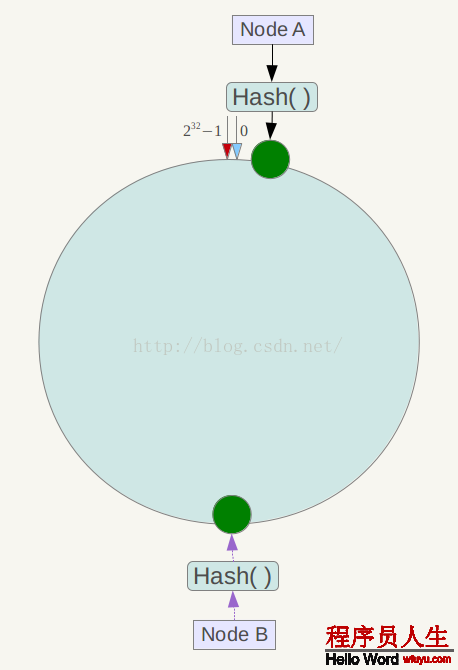
此時(shí)必定造成大量數(shù)據(jù)集中到Node A上,而只有極少許會定位到Node B上。為了解決這類數(shù)據(jù)傾斜問題,1致性哈希算法引入了虛擬節(jié)點(diǎn)機(jī)制,即對每個(gè)服務(wù)節(jié)點(diǎn)計(jì)算多個(gè)哈希,每一個(gè)計(jì)算結(jié)果位置都放置1個(gè)此服務(wù)節(jié)點(diǎn),稱為虛擬節(jié)點(diǎn)。具體做法可以在服務(wù)器ip或主機(jī)名的后面增加編號來實(shí)現(xiàn)。例如上面的情況,可以為每臺服務(wù)器計(jì)算3個(gè)虛擬節(jié)點(diǎn),因而可以分別計(jì)算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值,因而構(gòu)成6個(gè)虛擬節(jié)點(diǎn):
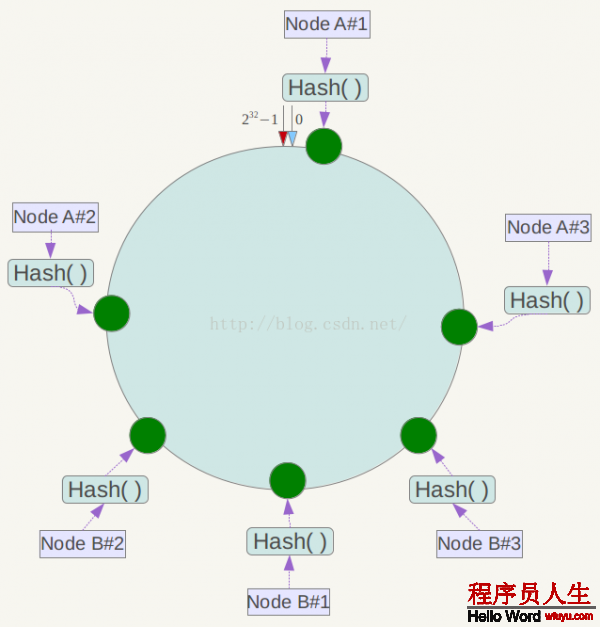
同時(shí)數(shù)據(jù)定位算法不變,只是多了1步虛擬節(jié)點(diǎn)到實(shí)際節(jié)點(diǎn)的映照,例如定位到“Node A#1”、“Node A#2”、“Node A#3”3個(gè)虛擬節(jié)點(diǎn)的數(shù)據(jù)均定位到Node A上。這樣就解決了服務(wù)節(jié)點(diǎn)少時(shí)數(shù)據(jù)傾斜的問題。在實(shí)際利用中,通常將虛擬節(jié)點(diǎn)數(shù)設(shè)置為32乃至更大,因此即便很少的服務(wù)節(jié)點(diǎn)也能做到相對均勻的數(shù)據(jù)散布。
[1]. D. Darger, E. Lehman, T. Leighton, M. Levine, D. Lewin and R. Panigrahy. Consistent Hashing and Random Trees:Distributed Caching Protocols for Relieving Hot Spots On the World Wide Web. ACM Symposium on Theory of Computing, 1997. 1997:654⑹63.
[2]. 1致性哈希. http://baike.baidu.com/view/1588037.htm
[3]. memcached全面剖析–4. memcached的散布式算法. http://tech.idv2.com/2008/07/24/memcached-004/
[4]. 1致性哈希算法及其在散布式系統(tǒng)中的利用. http://www.codinglabs.org/html/consistent-hashing.html
[5]. Consistent hashing. http://en.wikipedia.org/wiki/Consistent_hashing
[6]. http://www.lexemetech.com/2007/11/consistent-hashing.html

上一篇 Flume之監(jiān)控
下一篇 HDFS內(nèi)存存儲
程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學(xué)習(xí),php手冊,CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學(xué)習(xí),原版權(quán)很多不明,如有侵權(quán)請聯(lián)系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權(quán)所有


