
Aerospike是1個散布式可擴大的NoSql數據庫,為1下3個主要目標而構建:
最早發布于Proceedings of VLDB (Very Large Databases) in 2011,Aerospike架構包括3層:
Aerospike“智能客戶端”為速度而設計。它被實現為1個開源可鏈接庫用于C、c#、Java、PHP和Python開發,開發者可用自由按需發布或修改。客戶端包括以下內容
這類架構減少了事務延遲,分流集群工作并消除開發者工作量。它確保在節點啟停是利用沒必要重啟。總之,它消除對額外集群管理服務器或代理服務器的需要。
Aerospike “shared nothing”架構被設計目的是可以可靠存儲TB及數據并支持自動容錯、復制、跨數據中心同步。本層實現線性擴大及ACID guarantees。散布層也旨在消除手工操作,實現系統所有集群管理功能的自動化。它包括3個模塊:
Cluster Management Module用于追蹤集群節點。關鍵算法是肯定哪些節點是集群的1部份的Paxos-like1致投票進程。Aerospike實現專門的心跳檢測(主動與被動),用于監控節點間的連通性。
當1個節點被添加或移除并且集群成員被肯定,每一個節點使用哈希算法講主索引空間切分為數據切片并指派其具有者。Data Migration Module(數據遷移模塊)然后智能平衡跨集群中各節點的數據散布,并依照系統配置的復制因子確保每一個數據塊夸節點和夸數據中心復制。數據分割是純潔算法,系統擴大無master,從而消除在同享環境下的其他額外配置。
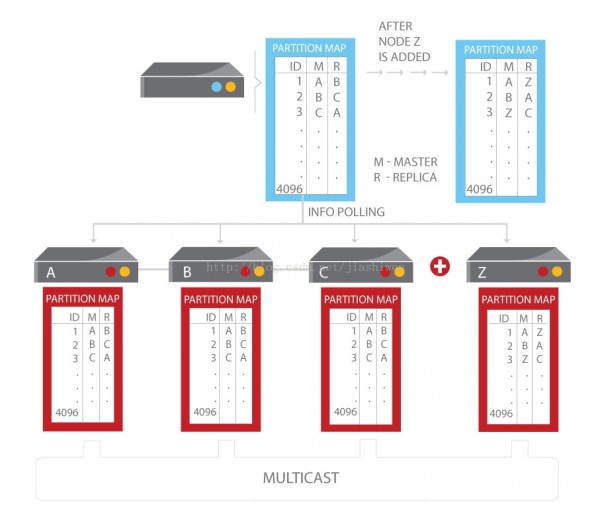
1旦啟動集群,你可以在其他數據中心安裝配置cross data-center replication的其他集群,如果集群崩潰,遠端集群可以承接負載。
Aerospike以無模式數據模型存儲鍵值對。組織數據的容器稱作命名空間(namespaces),相當于RDBMS系統中庫(databases )的概念。在namespace中數據被細分為各個集合(set)(類似數據庫中的表)和記錄(records )(類似數據庫中的行)。在set中每一個record有1個唯1的索引key和1個或多個bin(類似數據庫中的列)與之相干聯。
為了快速訪問,索引( primary keys 和 secondary keys)存儲于內存,數據可以存儲于內存或SSD硬盤。每一個namespace可以分別配置,這樣小的namespace可以存儲在內存而大的namespace可以存儲在SSD上。
在傳統(非散布式)數據庫系統中,安裝完軟件你需要設置schema、創建數據庫和表。這與Aerospike數據庫有很大不同。
在散布式數據庫中,數據散布在集群中的各個服務器上。這意味著你不能在1臺服務器上訪問到所有數據。
使用Aerospike 數據庫,將按以下步驟創建和管理數據庫:
通過配置初始化數據庫設置。按Aerospike的術語,當安裝系統時1個庫被稱作1個namespace,集群中的每一個節點必須指明每一個namespace如何創建及副本數量。數據庫講在你重啟服務的時候被創建
通過利用程序履行數據庫操作。當利用程序第1次援用set和bin的時候數據庫schema被創建,利用程序簡單地將數據存儲于指定的bin。在Aerospike數據庫中,任務通常由DBA通過命令行程序履行。
根據需要修改配置文件。要更新namespace的配置參數,你需要動態修改或使用新的配置文件重啟服務。
為滿足性能和冗余需求,Aerospike需要計劃和配置具體的節點數量,具體細節請參考 Capacity
Planning
可以通過management utilities 和 monitoring
tools管理和監控急大眾的節點。當添加節點或因升級保護需要宕機時集群會自動配置。當節點產生故障集群會再平衡負載,以便到達對終究用戶影響最小的目的。
1旦創建namespace,Aerospike提供了工具,允許您驗證數據庫存儲數據正確性。在生產數據庫,數據散布于集群當中。為了操作數據庫你需要在利用程序中實例化智能客戶端。智能終端是位置感知的,知道如何在集群中存儲/檢索數據而不影響性能。
Aerospike提供多種語言的API用于構建大數據利用程序。詳情參考客戶端手冊
編譯利用程序時,API函數庫隨智能終端被包括。為了在任何給定的時間肯定數據位置,智能終端延續監控集群狀態。智能客戶真個位置感知技術確保在大多數情況下,可以再1跳以內檢索到需要的數據。
當觸及到大數據利用時,例如基于web 的利用程序,情形以下:
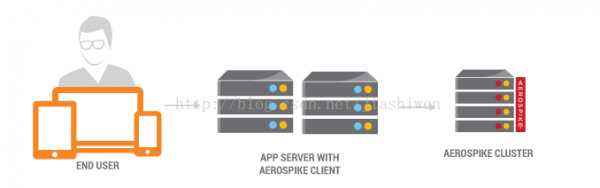
智能客戶端允許利用程序疏忽數據散布細節。具體細節請參閱architecture guide

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


