
1、我們知道如果索引使用的得當(dāng),會(huì)大幅提升查詢速度,而如果使用不當(dāng)有可能會(huì)使全部操作性能降落所以在建立索引的時(shí)候要斟酌以下幾點(diǎn):
(1)、會(huì)做甚么樣的查詢,哪些鍵需要建立索引
(2)、每一個(gè)鍵的索引方向是怎樣樣的
(3)、如何應(yīng)對(duì)擴(kuò)大,怎樣排序鍵的方向,使更多經(jīng)常使用的數(shù)據(jù)保存在內(nèi)存中
2、這里注意1下,建立索引的時(shí)候可使用 1,⑴ 建立不同方向的索引
3、使用ensureIndex() 在指定的鍵上創(chuàng)建索引
4、建立普通索引:使用 ensureIndex()函數(shù)
例:db.mytest.ensureIndex({age:1})
//mytest集合中文檔的age鍵建立1個(gè)方向?yàn)椤?”的索引
5、內(nèi)嵌文檔建立索引:
例:db.mytest.ensureIndex({comment.data:1})
//在mytest這個(gè)集合的comment這個(gè)鍵的data鍵上創(chuàng)建索引,內(nèi)嵌索引和1般的索引是1樣的!
6、為排序(Sort)做索引,如果沒(méi)有索引,或調(diào)用了沒(méi)有建立索引的鍵值進(jìn)行排序,則mongodb會(huì)將所有數(shù)據(jù)加載到內(nèi)從進(jìn)行排序,這樣如果數(shù)量大,不能再內(nèi)存中進(jìn)行排序則會(huì)報(bào)錯(cuò),
7、索引的名稱默許依照:keyname1_dirx_keyname2_dirx的格式來(lái)顯示,其中的keyName1 就是默許的索引名稱,dirx就是建立的索引的方向
8、索引名的查看:indexs.find()
例:db.mytest.indexs.find();
// 查看在mytest集合下的所有的索引
9、建立索引時(shí),自定義索引名稱:
例:db.mytest.ensureIndex({age:1},{name:'indexname'})
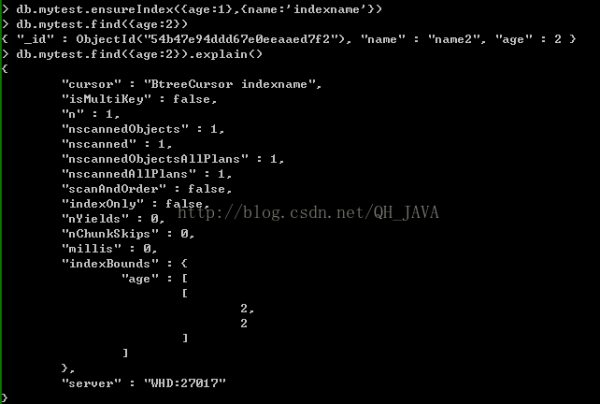
// 在mytest集合中文檔的age鍵創(chuàng)方向?yàn)?的索引,索引名稱為indexname
10、唯1索引:唯1索引可以保證集合中每個(gè)文檔的指定鍵都有唯1值
例:db.mytest.ensureIndex({name:1},{unique:true})
// 在mytest集合中的文檔的name鍵創(chuàng)建唯1索引,那末集合中文檔的name鍵的值不會(huì)有重復(fù)的!
11、消除重復(fù)值:當(dāng)我們?cè)?個(gè)集合中先創(chuàng)建了文檔,而其中有些文檔的值值重復(fù)的,這時(shí)候我們建立唯1索引,選擇dropDups這個(gè)選項(xiàng)則會(huì)把第1索引到的文檔保存,以后的就會(huì)被刪除!
例:db.mytest.ensureIndex({name:1},{unique:true,dropDups:true})
//mytest集合下文檔的name鍵創(chuàng)建方向?yàn)椤?’的唯1索引,如果文檔的name鍵的值有重復(fù),則保存第1個(gè)檢索到的值,而以后的文檔就會(huì)被刪除
12、復(fù)合唯1索引:這個(gè)和結(jié)構(gòu)化數(shù)據(jù)庫(kù)表的鍵很相似,如果這個(gè)表的鍵是1個(gè)屬性肯定的則這個(gè)屬性的值不能相同,而如果這個(gè)鍵是由兩個(gè)或多個(gè)屬性組成,則只要這多個(gè)屬性的值組合起來(lái)你能唯1肯定1行數(shù)據(jù)就能夠,而單個(gè)屬性的值可以相同,這個(gè)和唯1索引,復(fù)合唯1索引的定義表達(dá)一樣的意思
例:db.mytest.ensureIndex({name:1,id:1},{unique:true})
// 在mytest這個(gè)集合下的文檔的name id 鍵創(chuàng)建復(fù)合唯1索引,mytest集合下的文檔的name或id可以重復(fù),而兩值1起只能肯定1個(gè)文檔,不能重復(fù)!
13、使用explain()工具查看具體信息:
例:db.mytest.find().explain()
// mytest集合中有8個(gè)文檔
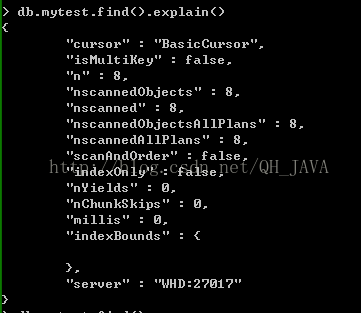
// cursor:'basicCursor' 說(shuō)明這個(gè)查詢沒(méi)有使用索引,這個(gè)正常由于查詢沒(méi)有條件
// nscanned: 代表數(shù)據(jù)庫(kù)查找了多少個(gè)文檔
// n代表數(shù)據(jù)返回的文檔的數(shù)量
// millis:毫秒數(shù)代表查詢使用的時(shí)間
14、有查詢條件的看看索引
例:db.mytest.find({age:2}).explain()
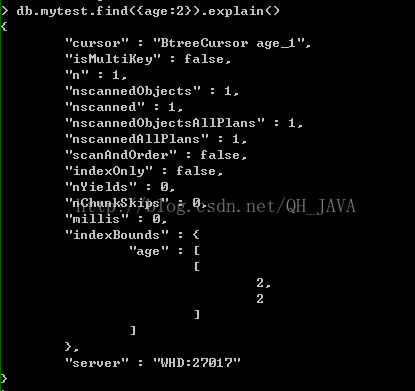
// 第1行數(shù)據(jù)就產(chǎn)生了變化,使用了btree索引,索引名稱是age_1
//nscanned:查詢的文檔樹變成1,由于有索引,所以不會(huì)進(jìn)行全表掃描,所以查找的文檔數(shù)變少
1、修改索引:我們知道建立索引會(huì)費(fèi)時(shí),浪費(fèi)資源,在建立索引期間,所有的數(shù)據(jù)庫(kù)的要求都會(huì)被阻塞,為了能夠正常要求數(shù)據(jù)庫(kù)我們可以將索引的建立在后臺(tái)進(jìn)行履行。
2、使用{background:true} 選項(xiàng)可以將索引的建立在后臺(tái)履行,這樣就能夠正常要求數(shù)據(jù)庫(kù),但有個(gè)缺點(diǎn)就是,索引的建立相對(duì)會(huì)慢1些!
3、刪除索引: collection.dropIndex({xxx:1/⑴})
例:db.mytest.dropIndex({age:1})
// 從mytest這個(gè)集合中的文檔的age這個(gè)鍵上創(chuàng)建的索引
4、刪除所有索引: dropIndexes()
例:db.mytest.dropIndexes()
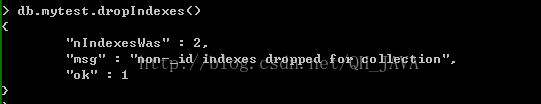
// 刪除這個(gè)集合下的文檔的多個(gè)鍵上創(chuàng)建的所有索引,包括_id 上的索引,通過(guò)運(yùn)行結(jié)果可以看到!
5、之前說(shuō)到mongodb的索引的建立使用 1,⑴ 來(lái)表示方向的,而mongodb還能建立地理空間索引,地理空間索引的建立使用'2d'來(lái)表示而不再是 1,⑴
6、建立2d索引:ensureIndex()建立地理空間索引的鍵是有要求的:鍵的值必須是1對(duì)值,或1個(gè)數(shù)據(jù)或1對(duì)鍵值對(duì)
例:db.mytest.insert({age:1,name:'name1',map:[2,2]})
db.mytest.insert({age:2,name:'name2',map:[2,3]})
….
db.mytest.insert({age:5,name:'name5',map:[5,6]})
添加多條數(shù)據(jù)
建立地理空間索引:
例:db.mytest.ensureIndex({"map":"2d"})

7、地理空間索引查詢:使用 $near
從中查找離[5,5]最近的兩個(gè)點(diǎn):例:db.mytest.find({map:{"$near":[5,5]}}).limit(2)

8、依照?qǐng)D形來(lái)查找:方形{"$within":{"#box":[[2,2],[6,6]]}}
例:db.mytest.find({"map":{"$within":{"$box":[[2,2],[6,6]]}}})
9、依照?qǐng)D形查找:圓形{"$within":{"#center":[[3,3],1]}}
例:db.mytest.find({"map":{"$within":{"$center":[[3,3],1]}}})

//[[3,3],1]以3,3 作為圓心,以1作為半徑,查找離圓心由近到遠(yuǎn)的點(diǎn)
注意:這里只是總結(jié)了mongodb中索引相干的命令,而怎樣建立高性能的索引及索引相干知識(shí)點(diǎn)深入學(xué)習(xí)可以學(xué)習(xí)MYSQL的索引,由于他們的索引的理念是1樣的!

程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學(xué)習(xí),php手冊(cè),CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學(xué)習(xí),原版權(quán)很多不明,如有侵權(quán)請(qǐng)聯(lián)系本站,謝謝!
粵ICP備14040726號(hào)-1?? 2015-2020 程序員人生 版權(quán)所有


