【HDFS】HDFS的整體架構設計,閱讀筆記
來源:程序員人生 發布時間:2015-03-23 08:10:51 閱讀次數:2851次
HDFS是1個高度容錯性的系統,合適部署在便宜的機器上。
HDFS可能由成百上千的
服務器構成,每一個
服務器上存儲著文件系統的部份數據,構成系統的組件數目是巨大的,任1組件都有可能失效,這意味著總是有1部份HDFS的組件是不工作的,所以
HDFS的核心架構目標是毛病檢測和快速、自動的恢復。
HDFS上的1個典型文件大小1般都在G字節至T字節
1個單1的HDFS實例應當能支持數以千萬計的文件
HDFS利用需要1個“1次寫入屢次讀取”的文件訪問模型。1個文件經過創建、寫入和關閉以后就不需要改變。這1假定簡化了數據1致性問題,并且使高吞吐量的數據訪問成為可能。
1個利用要求的計算,離它操作的數據越近就越高效,在數據到達海量級別的時候更是如此。
HDFS為利用提供了將它們自己移動到數據附近的接口。
架構
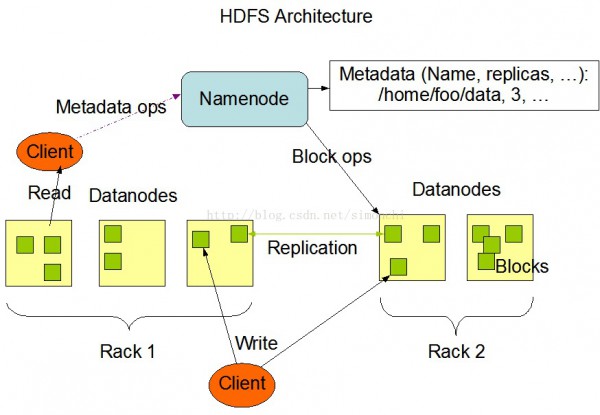
HDFS采取主從架構,1個HDFS集群有1個namenode和1定數目的datanode組成。
namenode是1個中心
服務器,負責管理文件系統的名字空間(namespace)和客戶端對文件的訪問(namenode去映照文件所在datanode)。
集群中的datanode1般是1個節點作為1個datanode,負責管理自己節點上的存儲。
1個文件被分成1個或多個數據塊,存儲在1組datanode上。
namenode負責履行文件系統操作,肯定數據塊到具體datanode節點的映照。
datanode負責處理文件系統客戶真個讀寫要求,在namenode的統1調度下進行數據塊的創建、刪除、復制。
HDFS采取JAVA開發,因此任何支持java的機器都可以部署namenode和datanode
集群中單1Namenode的結構大大簡化了系統的架構。Namenode是所有HDFS元數據的仲裁者和管理者,這樣,用戶數據永久不會流過Namenode。
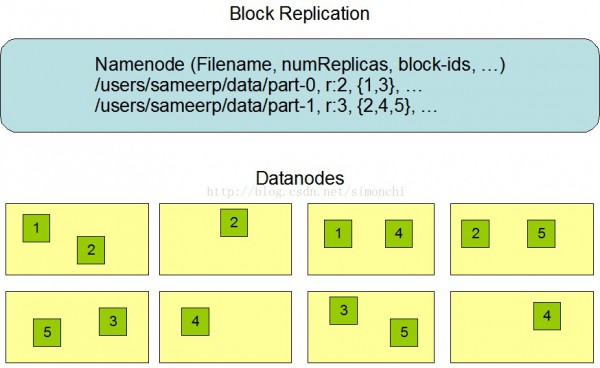
HDFS被設計成能夠在1個大集群中跨機器可靠地存儲超大文件。它將每一個文件存儲成1系列的數據塊,除最后1個,所有的數據塊都是一樣大小的。為了容錯,文件的所有數據塊都會有副本。每一個文件的數據塊大小和副本系數都是可配置的。利用程序可以指定某個文件的副本數目。副本系數可以在文件創建的時候指定,也能夠在以后改變。HDFS中的文件都是1次性寫入的,并且嚴格要求在任什么時候候只能有1個寫入者。
Namenode全權管理數據塊的復制,它周期性地從集群中的每一個Datanode接收心跳信號和塊狀態報告(Blockreport)。接收到心跳信號意味著該Datanode節點工作正常。塊狀態報告包括了1個該Datanode上所有數據塊的列表。
HDFS采取1種稱為機架感知(rack-aware)的策略來改進數據的可靠性、可用性和網絡帶寬的利用率。
通過1個機架感知的進程,Namenode可以肯定每一個Datanode所屬的機架id。1個簡單但沒有優化的策略就是將副本寄存在不同的機架上。這樣可以有效避免當全部機架失效時數據的丟失,并且允許讀數據的時候充分利用多個機架的帶寬。這類策略設置可以將副本均勻散布在集群中,有益于當組件失效情況下的負載均衡。但是,由于這類策略的1個寫操作需要傳輸數據塊到多個機架,這增加了寫的代價。
在大多數情況下,副本系數是3,HDFS的寄存策略是將1個副本寄存在本地機架的節點上,1個副本放在同1機架的另外一個節點上,最后1個副本放在不同機架的節點上。這類策略減少了機架間的數據傳輸,這就提高了寫操作的效力。機架的毛病遠遠比節點的毛病少,所以這個策略不會影響到數據的可靠性和可用性。于此同時,由于數據塊只放在兩個(不是3個)不同的機架上,所以此策略減少了讀取數據時需要的網絡傳輸總帶寬。在這類策略下,副本其實不是均勻散布在不同的機架上。3分之1的副本在1個節點上,3分之2的副本在1個機架上,其他副本均勻散布在剩下的機架中,這1策略在不侵害數據可靠性和讀取性能的情況下改進了寫的性能。
HDFS會盡可能讓讀取程序讀取離它最近的副本
namenode啟動后會進入1個安全模式的特殊狀態,這時候候不會進行塊復制,但是會通過塊狀態報告確認是不是安全(數據塊副本到達最小值的比例),安全后則退出,后續會肯定哪些塊副本未達標的將進行塊復制。
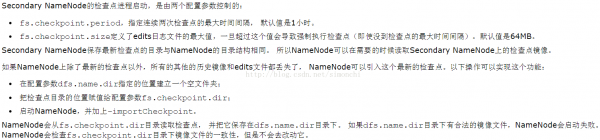
EditLog事務日志,FsImage文件塊映照、文件屬性等
namenode在內存中保存映照表,這個數據結構設計緊湊,4G內存的namenode足夠支持大量的文件和目錄;
當namenode啟動時,從硬盤讀取EditLog和FsImage,將所有的EditLog中的事務作用在內存的FsImage上,并將新的FsImage從內存保存到磁盤上,然后刪除舊的EditLog,這就是檢查點進程。
如果namenode很久都沒有啟動,那末EditLog是否是漸漸變的愈來愈大了(由于只有啟動才會合并fsimage和edits),下1次啟動很慢!!
所以secondary namenode就應運而生了,負責定期合并fsimage和edits,將edits日志大小控制在1個限度下。和namenode在不同機器上
datanode啟動時,掃描本地文件系統,產生1個本地文件對應的所有HDFS數據塊的列表,將這塊狀態報告發送給namenode。
FsImage和Editlog是HDFS的核心數據結構。如果這些文件破壞了,全部HDFS實例都將失效。
因此,Namenode可以配置成支持保護多個FsImage和Editlog的副本。任何對FsImage或Editlog的修改,都將同步到它們的副本上。這類多副本的同步操作可能會下降Namenode每秒處理的名字空間事務數量。但是這個代價是可以接受的,由于即便HDFS的利用是數據密集的,它們也非元數據密集的。當Namenode重啟的時候,它會選取最近的完全的FsImage和Editlog來使用。
網絡毛病的解決,datanode失效??
每一個datanode節點周期性的想namenode發送心跳信號。網絡斷開可能致使1部份datanode和namenode失去聯系,namenode通過心跳信號的缺失將此datanode標記為宕機,不會在將新的IO要求發給它們。這進1步致使1些數據塊的副本系數降落,namenode會不斷檢測需要復制的塊并啟動復制操作。
DFSAdmin
hadoop is deprecated,use hdfs
如何知道誰是admin呢??
啟動NameNode的用戶被視為HDFS的超級用戶
副本系數減小
namenode感知到會將過剩的副本刪除,下個心跳會將該信息傳遞給datanode,datanode行將數據塊刪除,空閑空間加大。
fsck用來檢查文件系統
用法:hadoop fsck [GENERIC_OPTIONS]
<path> [-move | -delete | -openforwrite] [-files [-blocks [-locations | -racks]]]
生活不易,碼農辛苦
如果您覺得本網站對您的學習有所幫助,可以手機掃描二維碼進行捐贈