redis之字符串命令源碼解析(二)
來源:程序員人生 發(fā)布時間:2014-11-22 08:40:07 閱讀次數(shù):2643次
形象化設(shè)計模式實戰(zhàn) HELLO!架構(gòu)
redis命令源碼解析
在redis之字符串命令源碼解析(1)中講了get的簡單實現(xiàn),并沒有對如何取到數(shù)據(jù)做深入分析,這里將深入。
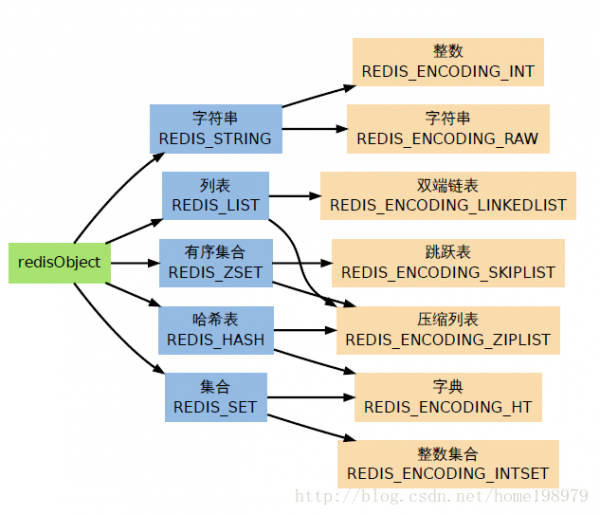
1、redisObject 數(shù)據(jù)結(jié)構(gòu),和Redis 的數(shù)據(jù)類型
(1)中說set test "hello redis",“hello redis”會終究保存在robj中,redisObject是Redis的核心,http://www.vxbq.cn/db/的每一個鍵、值,和Redis本身處理的參數(shù)都表示為這類數(shù)據(jù)類型,其結(jié)構(gòu)以下:
/* The actual Redis Object */
/*
* Redis 對象
*/
#define REDIS_LRU_BITS 24
#define REDIS_LRU_CLOCK_MAX ((1<<REDIS_LRU_BITS)⑴) /* Max value of obj->lru */
#define REDIS_LRU_CLOCK_RESOLUTION 1000 /* LRU clock resolution in ms */
typedef struct redisObject {
// 類型,冒號后面跟數(shù)字,表示包括的位數(shù),這樣更節(jié)省內(nèi)存
unsigned type:4;
// 編碼
unsigned encoding:4;
// 對象最后1次被訪問的時間
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
// 援用計數(shù)
int refcount;
<span style="color:#ff0000;">// 指向?qū)嶋H值的指針,指向上節(jié)的sdshdr->buf,而不是sdshdr,這還要歸因于sds.c中的方法sdsnewlen返回的buf部份,而不是全部sdshdr</span>
void *ptr;
} robj;
對象類型有:
#define REDIS_STRING 0 // 字符串
#define REDIS_LIST 1 // 列表
#define REDIS_SET 2 // 集合
#define REDIS_ZSET 3 // 有序集
#define REDIS_HASH 4 // 哈希表
對象編碼有:
#define REDIS_ENCODING_RAW 0 // 編碼為字符串
#define REDIS_ENCODING_INT 1 // 編碼為整數(shù)
#define REDIS_ENCODING_HT 2 // 編碼為哈希表
#define REDIS_ENCODING_ZIPMAP 3 // 編碼為zipmap
#define REDIS_ENCODING_LINKEDLIST 4 // 編碼為雙端鏈表
#define REDIS_ENCODING_ZIPLIST 5 // 編碼為緊縮列表
#define REDIS_ENCODING_INTSET 6 // 編碼為整數(shù)集合
#define REDIS_ENCODING_SKIPLIST 7 // 編碼為跳躍表
2、內(nèi)部數(shù)據(jù)結(jié)構(gòu)之dict(俗稱字典)
1.1 dict結(jié)構(gòu)
Redis使用的是高效且實現(xiàn)簡單的哈希作為字典的底層實現(xiàn)。
dict.h中定義以下:
/*
* 字典
*/
typedef struct dict {
// 類型特定函數(shù)
dictType *type;
// 私有數(shù)據(jù)
void *privdata;
// 哈希表
dictht ht[2];
// rehash 索引
// 當(dāng) rehash 不在進行時,值為 ⑴
int rehashidx; /* rehashing not in progress if rehashidx == ⑴ */
// 目前正在運行的安全迭代器的數(shù)量
int iterators; /* number of iterators currently running */
} dict;
哈希表dictht的結(jié)構(gòu):
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
/*
* 哈希表
*
* 每一個字典都使用兩個哈希表,從而實現(xiàn)漸進式 rehash 。
*/
typedef struct dictht {
// 哈希表數(shù)組
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩碼,用于計算索引值
// 總是等于 size - 1
unsigned long sizemask;
// 該哈希表已有節(jié)點的數(shù)量
unsigned long used;
} dictht;
哈希表數(shù)組dictEntry的結(jié)構(gòu):/*
* 哈希表節(jié)點
*/
typedef struct dictEntry {
// 鍵
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下個哈希表節(jié)點,構(gòu)成鏈表
struct dictEntry *next;
} dictEntry;
那末1個dict可以圖解表示為:
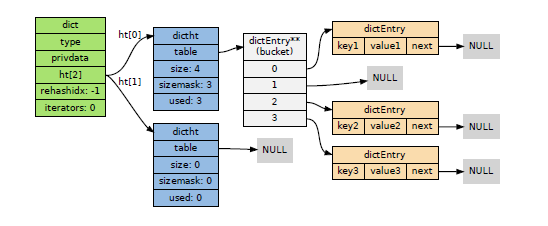
由圖可清晰地看出redis字典哈希表所使用的哈希碰撞解決方法是鏈地址法,這個方法就是使用鏈表將多個哈希值相同的節(jié)點串聯(lián)在1起,從而解決沖突問題。
1.2 dict實現(xiàn)setCommand
set命令終究會調(diào)用dict.c中的dictAdd方法將test => "hello redis" 保存到字典中
/* Add an element to the target hash table */
/*
* 嘗試將給定鍵值對添加到字典中
*
* 只有給定鍵 key 不存在于字典時,添加操作才會成功
*
* 添加成功返回 DICT_OK ,失敗返回 DICT_ERR
*
* 最壞 T = O(N) ,平灘 O(1)
*/
int dictAdd(dict *d, void *key, void *val)
{
// 嘗試添加鍵到字典,并返回包括了這個鍵的新哈希節(jié)點
// T = O(N)
dictEntry *entry = dictAddRaw(d,key);
// 鍵已存在,添加失敗
if (!entry) return DICT_ERR;
// 鍵不存在,設(shè)置節(jié)點的值
// T = O(1)
dictSetVal(d, entry, val);
// 添加成功
return DICT_OK;
}
全部set可簡略以下圖(此圖省去了許多其它操作):
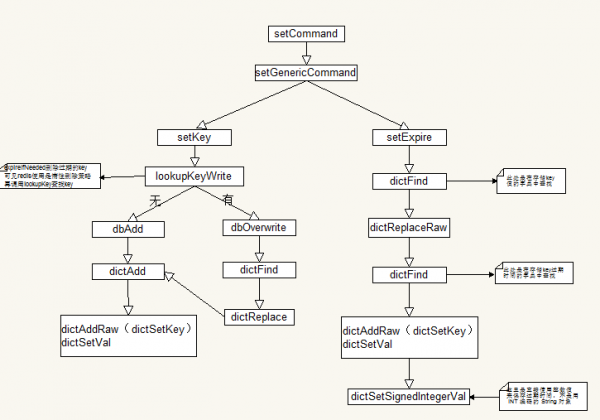
從圖中你會發(fā)現(xiàn),其實key的過期時間就相當(dāng)因而key的另外一個val,保存在另外一個dict中,簡單地說就是有兩個dict,1個是key=>value,1個是key=>expire。
1.3 dict哈希表的rehash
dict有兩個ht,就是每一個字典有兩個哈希表,為毛要有兩個,其作用是對dict進行擴容和收縮,由于如果節(jié)點數(shù)量比哈希表的大小要大很多的話,那末哈希表就會退化成多個鏈表,哈希表本身的性能優(yōu)勢就不再存在。
dict.c中的_dictExpandIfNeeded方法對哈希表什么時候可rehash作了判斷:
// 1下兩個條件之1為真時,對字典進行擴大
// 1)字典已使用節(jié)點數(shù)和字典大小之間的比率接近 1:1
// 并且 dict_can_resize 為真
// 2)已使用節(jié)點數(shù)和字典大小之間的比率超過 dict_force_resize_ratio(默許值為5)
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
// 新哈希表的大小最少是目前已使用節(jié)點數(shù)的兩倍
// T = O(N)
return dictExpand(d, d->ht[0].used*2);
<span style="white-space:pre"> </span>//dictExpand的進程就是獲得ht[0]的size,然后copy到ht[1]中,就是table大小是目錄使用節(jié)點數(shù)的兩倍。最后再將rehashidx設(shè)為0,標(biāo)識著可以進行rehash了
}
rehash的代碼這里不貼出,由于實現(xiàn)簡單,大致的進程是
1. 釋放ht[0] 的空間;
2. 用ht[1] 來代替ht[0] ,使原來的ht[1] 成為新的ht[0] ;
3. 創(chuàng)建1個新的空哈希表,并將它設(shè)置為ht[1] ;
4. 將字典的rehashidx 屬性設(shè)置為⑴ ,標(biāo)識rehash 已停止;
但我在看源代碼時,發(fā)現(xiàn)其實不是1將rehashidx設(shè)為0就進行rehash操作的,而是當(dāng)再次dictAdd時,才dictRehash(d,1),第2個參數(shù)是1,也就是說每次rehash只會對單個索引上的節(jié)點進行遷移,這類做法幾近不會消耗甚么時間,客戶端可以快速的得到響應(yīng)。固然這類除這類方式進行rehash外,Redis還有個定時任務(wù)調(diào)用dictRehashMilliseconds方法,在規(guī)定的時間內(nèi),盡量地對http://www.vxbq.cn/db/字典中那些需要rehash的字典進行rehash,從而加速rehash的進程。
現(xiàn)在我知道Redis其實不是1下子就rehash完成,而是需要1定時間的,那末如果客戶端在這段時間內(nèi)向Redis發(fā)送get set del要求,那Redis會如何處理,從而保證數(shù)據(jù)的完全和正確呢?
? 由于在rehash 時,字典會同時使用兩個哈希表,所以在這期間的所有查找、刪除等操作,除在ht[0] 上進行,還需要在ht[1] 上進行。
? 在履行添加操作時,新的節(jié)點會直接添加到ht[1] 而不是ht[0] ,這樣保證ht[0] 的節(jié)點數(shù)量在全部rehash 進程中都只減不增。
生活不易,碼農(nóng)辛苦
如果您覺得本網(wǎng)站對您的學(xué)習(xí)有所幫助,可以手機掃描二維碼進行捐贈