Hive學習(九)Hive體系結構
來源:程序員人生 發布時間:2014-11-12 09:04:12 閱讀次數:4605次
1、Hive架構與基本組成
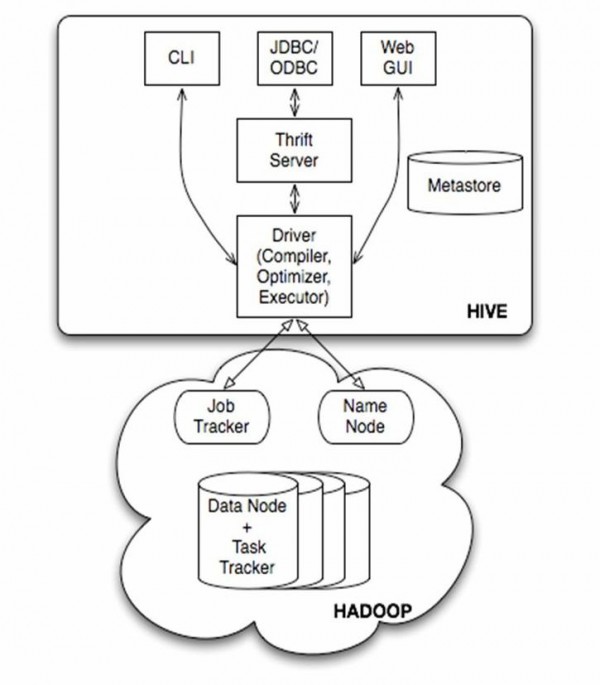
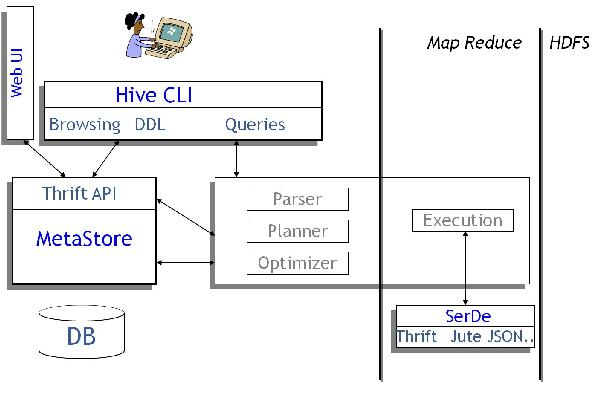
下面是Hive的架構圖。
圖1.1 Hive體系結構
Hive的體系結構可以分為以下幾部份:
(1)用戶接口主要有3個:CLI,Client 和 WUI。其中最經常使用的是CLI,Cli啟動的時候,會同時啟動1個Hive副本。Client是Hive的客戶端,用戶連接至Hive Server。在啟動 Client模式的時候,需要指出Hive Server所在節點,并且在該節點啟動Hive Server。 WUI是通過閱讀器訪問Hive。
(2)Hive將元數據存儲在http://www.vxbq.cn/db/中,如mysql、derby。Hive中的元數據包括表的名字,表的列和分區及其屬性,表的屬性(是不是為外部表等),表的數據所在目錄等。
(3)解釋器、編譯器、優化器完成HQL查詢語句從詞法分析、語法分析、編譯、優化和查詢計劃的生成。生成的查詢計劃存儲在HDFS中,并在隨后有MapReduce調用履行。
(4)Hive的數據存儲在HDFS中,大部份的查詢、計算由MapReduce完成(包括*的查詢,比如select * from tbl不會生成MapRedcue任務)。
Hive將元數據存儲在RDBMS中,
有3種模式可以連接到http://www.vxbq.cn/db/:
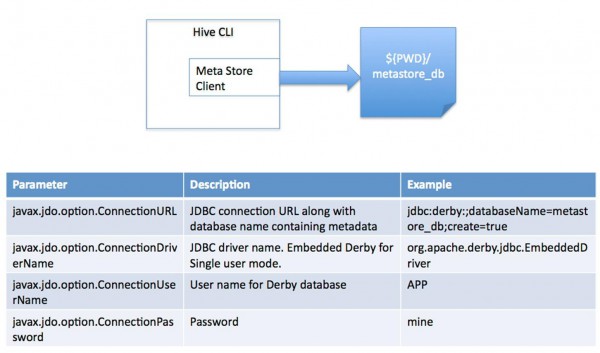
(1) 單用戶模式。此模式連接到1個In-memory 的http://www.vxbq.cn/db/Derby,1般用于Unit Test。
圖2.1 單用戶模式
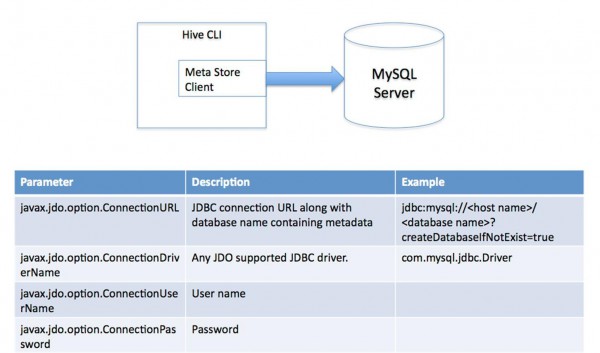
(2)多用戶模式。通過網絡連接到1個http://www.vxbq.cn/db/中,是最常常使用到的模式。
圖2.2 多用戶模式
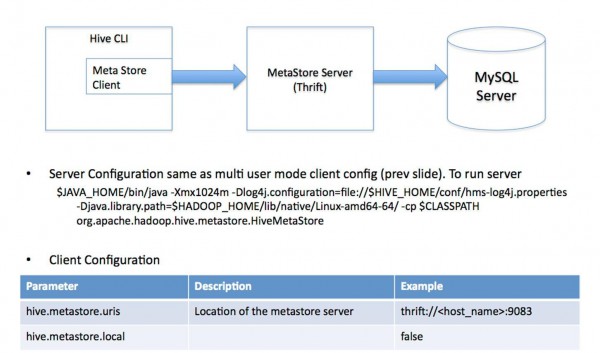
(3) 遠程http://www.vxbq.cn/server/模式。用于非Java客戶端訪問元http://www.vxbq.cn/db/,在http://www.vxbq.cn/server/端啟動MetaStoreServer,客戶端利用Thrift協議通過MetaStoreServer訪問元http://www.vxbq.cn/db/。
對數據存儲,Hive沒有專門的數據存儲格式,也沒有為數據建立索引,用戶可以非常自由的組織Hive中的表,只需要在創建表的時候告知Hive數據中的列分隔符和行分隔符,Hive就能夠解析數據。Hive中所有的數據都存儲在HDFS中,存儲結構主要包括http://www.vxbq.cn/db/、文件、表和視圖。Hive中包括以下數據模型:Table內部表,External Table外部表,Partition分區,Bucket桶。Hive默許可以直接加載文本文件,還支持sequence file 、RCFile。
Hive的數據模型介紹以下:
(1)Hivehttp://www.vxbq.cn/db/
類似傳統http://www.vxbq.cn/db/的DataBase,在第3方http://www.vxbq.cn/db/里實際是1張表。簡單示例命令行 hive > create database test_database;
(2)內部表
Hive的內部表與http://www.vxbq.cn/db/中的Table在概念上是類似。每個Table在Hive中都有1個相應的目錄存儲數據。例如1個表pvs,它在HDFS中的路徑為/wh/pvs,其中wh是在hive-site.xml中由${hive.metastore.warehouse.dir} 指定的數據倉庫的目錄,所有的Table數據(不包括External Table)都保存在這個目錄中。刪除表時,元數據與數據都會被刪除。
內部表簡單示例:
創建數據文件:test_inner_table.txt
創建表:create table test_inner_table (key string)
加載數據:LOAD DATA LOCAL INPATH ‘filepath’ INTO TABLE test_inner_table
查看數據:select * from test_inner_table; select count(*) from test_inner_table
刪除表:drop table test_inner_table
(3)外部表
外部表指向已在HDFS中存在的數據,可以創建Partition。它和內部表在元數據的組織上是相同的,而實際數據的存儲則有較大的差異。內部表的創建進程和數據加載進程這兩個進程可以分別獨立完成,也能夠在同1個語句中完成,在加載數據的進程中,實際數據會被移動到數據倉庫目錄中;以后對數據對訪問將會直接在數據倉庫目錄中完成。刪除表時,表中的數據和元數據將會被同時刪除。而外部表只有1個進程,加載數據和創建表同時完成(CREATE
EXTERNAL TABLE ……LOCATION),實際數據是存儲在LOCATION后面指定的 HDFS 路徑中,其實不會移動到數據倉庫目錄中。當刪除1個External Table時,僅刪除該鏈接。
外部表簡單示例:
創建數據文件:test_external_table.txt
創建表:create external table test_external_table (key string)
加載數據:LOAD DATA INPATH ‘filepath’ INTO TABLE test_inner_table
查看數據:select * from test_external_table; ?select count(*) from test_external_table
刪除表:drop table test_external_table
(4)分區
Partition對應于http://www.vxbq.cn/db/中的Partition列的密集索引,但是Hive中Partition的組織方式和http://www.vxbq.cn/db/中的很不相同。在Hive中,表中的1個Partition對應于表下的1個目錄,所有的Partition的數據都存儲在對應的目錄中。例如pvs表中包括ds和city兩個Partition,則對應于ds = 20090801, ctry = US 的HDFS子目錄為/wh/pvs/ds=20090801/ctry=US;對應于 ds = 20090801, ctry = CA 的HDFS子目錄為/wh/pvs/ds=20090801/ctry=CA。
分區表簡單示例:
創建數據文件:test_partition_table.txt
創建表:create table test_partition_table (key string) partitioned by (dt string)
加載數據:LOAD DATA INPATH ‘filepath’ INTO TABLE test_partition_table partition (dt=‘2006’)
查看數據:select * from test_partition_table; select count(*) from test_partition_table
刪除表:drop table test_partition_table
(5)桶
Buckets是將表的列通過Hash算法進1步分解成不同的文件存儲。它對指定列計算hash,根據hash值切分數據,目的是為了并行,每個Bucket對應1個文件。例如將user列分散至32個bucket,首先對user列的值計算hash,對應hash值為0的HDFS目錄為/wh/pvs/ds=20090801/ctry=US/part-00000;hash值為20的HDFS目錄為/wh/pvs/ds=20090801/ctry=US/part-00020。如果想利用很多的Map任務這樣是不錯的選擇。
桶的簡單示例:
創建數據文件:test_bucket_table.txt
創建表:create table test_bucket_table (key string) clustered by (key) into 20 buckets
加載數據:LOAD DATA INPATH ‘filepath’ INTO TABLE test_bucket_table
查看數據:select * from test_bucket_table; set hive.enforce.bucketing = true;
(6)Hive的視圖
視圖與傳統http://www.vxbq.cn/db/的視圖類似。視圖是只讀的,它基于的基本表,如果改變,數據增加不會影響視圖的顯現;如果刪除,會出現問題。?如果不指定視圖的列,會根據select語句后的生成。
示例:create view test_view as select * from test
2、Hive的履行原理
圖2.1 Hive的履行原理
Hive構建在Hadoop之上,
(1)HQL中對查詢語句的解釋、優化、生成查詢計劃是由Hive完成的
(2)所有的數據都是存儲在Hadoop中
(3)查詢計劃被轉化為MapReduce任務,在Hadoop中履行(有些查詢沒有MR任務,如:select * from table)
(4)Hadoop和Hive都是用UTF⑻編碼的
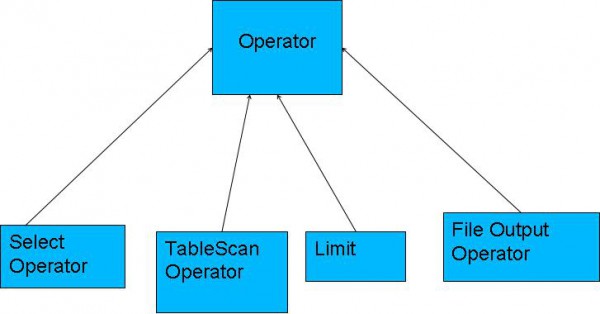
Hive編譯器將1個Hive QL轉換操作符。操作符Operator是Hive的最小的處理單元,每一個操作符代表HDFS的1個操作或1道MapReduce作業。Operator都是hive定義的1個處理進程,其定義有:
protected List <Operator<? extends Serializable >> childOperators;
protected List <Operator<? extends Serializable >> parentOperators;
protected boolean done; // 初始化值為false
所有的操作構成了Operator圖,hive正是基于這些圖關系來處理諸如limit, group by, join等操作。
圖2.2 Hive QL的操作符
操作符以下:
TableScanOperator:掃描hive表數據
ReduceSinkOperator:創建將發送到Reducer真個<Key,Value>對
JoinOperator:Join兩份數據
SelectOperator:選擇輸出列
FileSinkOperator:建立結果數據,輸出至文件
FilterOperator:過濾輸入數據
GroupByOperator:GroupBy語句
MapJoinOperator:/*+mapjoin(t) */
LimitOperator:Limit語句
UnionOperator:Union語句
Hive通過ExecMapper和ExecReducer履行MapReduce任務。在履行MapReduce時有兩種模式,即本地模式和散布式模式 。
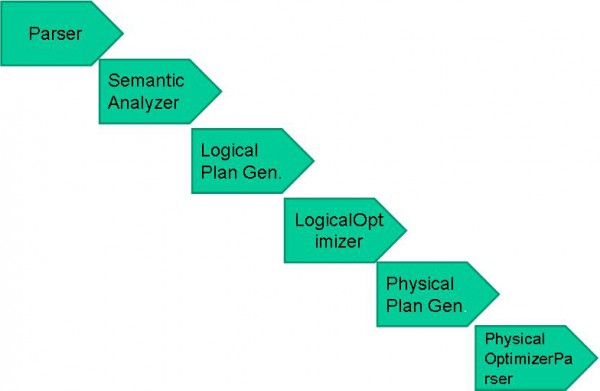
Hive編譯器的組成:
圖2.3 Hive編譯器的組成
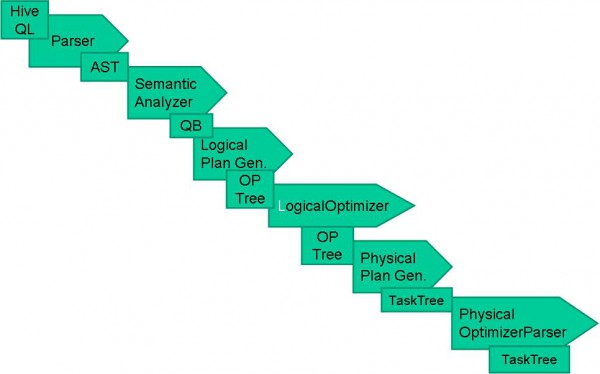
編譯流程以下:
圖2.4 Hive QL編譯流程
3、Hive和http://www.vxbq.cn/db/的異同
由于Hive采取了SQL的查詢語言HQL,因此很容易將Hive理解為http://www.vxbq.cn/db/。其實從結構上來看,Hive和http://www.vxbq.cn/db/除具有類似的查詢語言,再無類似的地方。http://www.vxbq.cn/db/可以用在Online的利用中,但是Hive是為數據倉庫而設計的,清楚這1點,有助于從利用角度理解Hive的特性。
Hive和http://www.vxbq.cn/db/的比較以下表:
(1)查詢語言。由于 SQL 被廣泛的利用在數據倉庫中,因此專門針對Hive的特性設計了類SQL的查詢語言HQL。熟習SQL開發的開發者可以很方便的使用Hive進行開發。
(2)數據存儲位置。Hive是建立在Hadoop之上的,所有Hive的數據都是存儲在HDFS中的。而http://www.vxbq.cn/db/則可以將數據保存在塊裝備或本地文件系統中。
&nb
生活不易,碼農辛苦
如果您覺得本網站對您的學習有所幫助,可以手機掃描二維碼進行捐贈

------分隔線----------------------------
------分隔線----------------------------