
印象筆記同步分享:《程序員面試寶典》學習記錄5
考點1:對容器保存的元素類型的限制
voctor<noDefault> v2(10) 錯誤,必須要提供一個原始初始化器
vector<int>v1(100) 初始化size為100 避免數組動態增長時候不斷分配內存
v1.reserve(100) 功能同上
考點2:vector常用的成員函數
c.back() 傳回最后一個數據,不檢查這個數據是否存在
c.front() 傳回第一個數據
c.push_back(elem) 在尾部加入一個數據
c.pop_back() 刪除最后一個數據
c.reserve() 保留適當的容量
c.at(idx) 返回索引idx所指向的數據,如果idx越界,拋出out of range
考點3:區分在順序容器中訪問元素的操作
vector<string> svec;
cout << svec[0]; 運行是錯誤,因為svec中沒有元素
cout << svec.at(0); 拋出一個out_of_range異常
考點4:刪除操作
c.erase(pos) 刪除pos位置的數據,傳回下一個數據的位置
c.erase(beg,end) 刪除[beg,end)區間的數據,傳回下一個數據的元素
c.erase(remove(c.begin(), c.end(), 6), c.end()) 刪除容器中所有的6
補充說明:STL中remove()只是把待刪除移動到vector的末尾,并不是刪除,要正在刪除還需要結合erase,但是對于vector,任何插入刪除操作都會引起迭代器失效,所有連續刪除的時候需要注意。需要注意刪除操作,刪除之后傳回下一個數據的位置,如果繼續iter++的話,會導致錯過某個數。
考點5:淺拷貝和深拷貝
C++默認的拷貝構造函數是淺拷貝
淺拷貝:對象的數據成員之間的簡單賦值,如你設計了一個沒有類而沒有提供它的復制構造函數,當用該類的一個對象去給令一個對象賦值時所執行的過程就是淺拷貝。
class A {
public:
A(int _data) : data(_data){}
A(){}
private:
int data;
};
int main()
{
A a(5);
A b = a; // 僅僅是數據成員之間的賦值
}
淺拷貝,執行完之后b.data = 5
如果對象中沒有其他的資源(如:堆,文件,系統資源等),則深拷貝和淺拷貝沒有什么區別,但當對象中有這些資源時,例子:
class A {
public:
A(int _size) : size(_size)
{
data = new int[size];
} // 假如其中有一段動態分配的內存
A(){};
~A(){delete [] data;} // 析構時釋放資源private:
int* data;
int size;
}
int main()
{
A a(5);
A b = a; // 注意這一句
}
運行會產生崩潰的現象
這里b的指針data和a的指針指向了堆上的同一塊內存,a和b析構時,b先把其data指向的動態分配的內存釋放了一次,而后a析構時又將這塊已經被釋放過的內存再釋放一次。
對同一塊動態內存執行2次以上釋放的結果是未定義的,所以這將導致內存泄露或程序崩潰。
所以必須采用深拷貝來解決這個問題:
深拷貝:當拷貝對象中有對其他資源(如堆、文件、系統等)的引用時候,對象的另開辟一塊新的資源,而不再對拷貝對象中有對其他資源的引用的的指針或者引用單純的賦值。
class A {
public: A(int _size) : size(_size)
{
data = new int[size];
} // 假如其中有一段動態分配的內存
A(){};
A(const A& _A) : size(_A.size)
{
data = new int[size];
} // 深拷貝
~A()
{
delete [] data;
} // 析構時釋放資源private:
int* data;
nt size;
}
int main()
{
A a(5);
A b = a; // 這次就沒問題了
}
考點1:如何理解泛型編程?
泛型編程是一種基于發現高效算法的最抽象表示的編程方法,主要作用是在函數的參數調用中將具體的數據類型隱去,能夠給通過模板(template)的方式,只是通過泛型指針來對數據進行調用操作,進而達到增加函數重復利用,以及代碼簡潔的目的。
泛型編程主要特點:
1)泛型編程集中的應用體現STL庫的調用,STL主要由容器、算法、迭代器三部分組成,迭代器iterator是連接不同容器和算法之間的橋梁
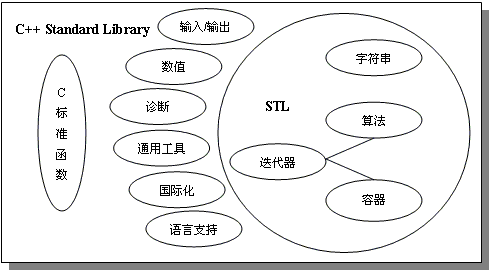
2)泛型算法主要的操作對象是不同的容器,但一般都是通過傳址方式調用,傳入參數的前兩個一般都是first iterator和last iterator;find(),sort(),replace(),merge()等都是泛型算法。
3)采用泛型算法和采用傳統面向過程風格的區別主要是一個函數可以使用的彈性更大,解決同樣的問題,采用泛型算法代碼會更加簡潔
考點2:如何把普通的函數改成泛型函數的問題?
普通的函數:
const int *find1(const int* array, int n, int x)
{
const int *p = array;
for(int i = 0; i < n; i++)
{
if(*p == x)
{
return p;
}
++p;
}
return 0;
}
泛型函數:
template<typename T>
const T *find1(T* array, T n, T x)
{
const T *p = array;
for(int i = 0; i < n; i++)
{
if(*p == x)
{
return p;
}
++p;
}
return 0;
}
方法:
對于容器的變量需要將原來的參數改為泛型指針傳遞;
對于數據的變量需要將原參數模板化,采用template定義;
對于函數指針,則需要通過定義函數對象來傳遞原指針;
對于泛型函數內部的操作,則必須避免出現底層的數據,用指針和函數對象來代替。
考點1:認識模板
模板是C++支持參數化多態的工具,使用模板可以使用戶為類或者函數聲明一種一般模式,使得類中的某些數據成員或者成員函數的參數、返回值取得任意類型。
模板通常有兩種形式:函數模板、類模板
函數模板僅參數類型不同的函數;類模板針對僅數據成員和成員函數類型不同的類。
模板的聲明或定義只能在全局,命名空間或類范圍內進行。即不能在局部范圍,函數內進行,比如不能在main函數中聲明或定義一個模板。
考點2:模板的形參
模板的形參表示的是一個未知的類型。
模板的形參:類型形參、非類型形參和模板形參
類型形參:T 前面一般是class或者typename
非類型形參:在模板定義的內部是常量值,也就是說非類型形參在模板的內部是常量;非類型模板的形參只能是整型,指針,引用;調用非類型模板形參必須是一個常量表達式,任何局部對象,局部變量,局部對象的地址都不是一個常量表達式,都不能用作非類型模板形參的實參。但是全局變量的地址或引用,全局對象的地址或引用const類型變量是常量表達式,可以用非類型模板形參的實參;非類型模板形參的形參和實參間允許轉換。
考點3:用模板把指針作為參數傳遞到其他函數
#include<stdio.h>
//比較函數
int jug(int x, int y)
{
if(x>=0)
{
return 0;
}
else if(y==0)
{
return x;
}
else
return x/y;
}
//求和函數
int sub(int x, int y)
{
return(x+y);
}
//求差函數
int minus(int x, int y)
{
return(x-y);
}
//函數指針
void test(int (*p)(int,int), int a, int b)
{
int Int1;
Int1 = (*p)(a,b);
printf("a=%d,a=%d %d
",a,b,Int1);
}
int main()
{
int a=1,b=2,c=3,d=4,e=-5;
test(sub,a,b); //求和
test(minus,c,d); //求差
test(jug,e,b);//判斷
return 0;
}
考點4:利用枚舉法
1~9的9個數字,每個數字只能出現一次,要求這樣一個9位的整數;其第一位能被1整除,前兩位能被2整除,前三位能被3整除……依次類推,前9位能被9整除
代碼:
#include<iostream>using namespace std;
bool use[10];//標記是否使用過void dfs(int k, long long val)
{
if(k==9)//9位則輸出
{
cout << val << endl;
return;
}
for(int i=1;i<=9;++i)
{
if(!used[i])
{
used[i]=1;
long long temp = val*10+i;
if(temp%(i+1)==0)
dfs(i+1,tmp);
used[i]=0;
}
}
}
int main()
{
dfs(0,0);
return 0;
}

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


