
近日,亞馬遜在其官方博客發布了AWS與Fluentd結合起來進行數據收集,存儲和處理的相關操作方法和案例,AWS和Fluentd的結合使數據處理更加快捷。
以下為譯文:
數據存儲便宜,但數據收集并不便宜
數據存儲十分便宜。但Kiyoto所說的便宜不是指其硬件很便宜,而是指數據的存儲操作以及人工成本非常便宜。感謝IaaS的應用,就像AWS,我們不需要再花費很多時間進行容量規劃(或者更好的是,可以用自動可擴展的方式提供資源)或者擔心我們的服務器發生故障。

相對便宜的存儲意味著我們的想法不再數據存儲量而束縛。僅需要少數工程師就可以在Amazon Simple Storage Service(S3)平臺中完成運行一組數據,或者是Redshift instances或者是管理大量日志數據備份,備份他們日常的工作記錄。分析海量的數據不再僅僅屬于那些獨享大全,精通技術的公司。
然而,數據收集仍然是一個重大挑戰:數據不會奇跡般的存儲在系統中或者進行自行整理。因此,許多(臨時)腳本被用作解析加載數據。這些腳本易變,易錯,而且幾乎不可能延伸。
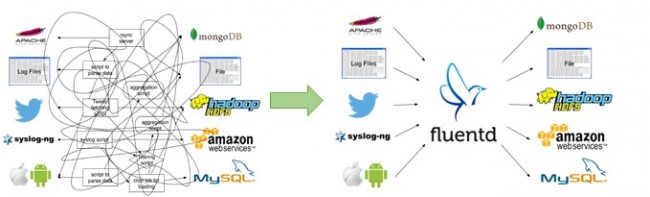
這些問題都是Fluentd嘗試要解決的:可擴展,靈活的實時收集數據。Kiyoto在博文中也講到Fluentd的基本結構,同時分享了一些AWS使用案例。
Fluentd:大容量數據流的開源數據采集器
Fluentd原本是寫在Treasure Data中的一個開源數據采集器。在2011年10月開源,并在過去的2年半時間獲得了穩步牽引:今天,我們有一個蓬勃發展的社區,在GitHub有50人的貢獻者和超過2100人的追隨者,與Slideshare公司和Nintendo共同部署數據生產。
輸入和輸出
在最高的等級,Fluentd包含輸入和輸出。輸入是指定Fluentd如何以及何時攝取數據。
普遍輸入是:
1.跟蹤日志文件和解析每行數據(或者同時解析多行數據)
2.接收系統日志信息
3.接收HTTP請求以及解析信息內容
輸入的兩個關鍵特征:JSON和標記
1.Fluentd采取JSON為它的核心數據形式,每個輸入的作用是將接通的輸入數據轉換為一系列的JSON“事件”。
2.每個輸入都為其攝取的數據提供了一個標簽。根據標簽,Fluentd決定如何處理不同來源的數據(如下)。
當數據通過Fluentd輸入 ,Fluentd標記每個事件(在2中有所解釋)然后指定線路輸出標記,例如本地文件系統,RDBMSs,NoSQL數據庫以及AWS服務。
開放和插件架構
為什么Fluentd已經有很多輸入以及輸出。秘訣是開放和插件架構。Ruby最基本的常識就是用戶可以在短時間內構建一個新的插件。毋庸置疑,許多Fluentd用戶非常熱衷于AWS,所以,我們已經在如下的AWS服務中安置插件:
1.Amazon Simple Storage Service(S3) (輸出)
2.Amazon Redshift (輸出)
3.Amazon Simple Queue Service (SQS) (輸入和輸出)
4.Amazon Kinesis (輸出)
5.Amazon DynamodB (輸出)
6.AWS CloudWatch (輸入)
性能和可靠性
當我“坦白”Fluentd大部分內容在Ruby中編寫的,客戶非常擔心Fluentd的性能。不用擔心,Fluentd非常快速,在現代的服務器中,它可以在單核中的處理速度達到15000次/秒,如果在多核中運行Fluentd,你可以獲得更好的輸出。
Fluentd可以達到這樣的速度是通過使用C語言底層類庫編寫軟件性能關鍵的部分。例如Fluentd運用Cool.io(Masahiro Nakagawa,Fluentd主要維護者)進行事件循環,和Ruby中的MessagePack(Sadayuki Furuhash,Fluentd的原作者)來提供內部數據形式。
速度很好,日志收集必須非常可靠:數據流失導致了壞數據和糟糕的決定。Fluentd通過緩沖來確保可靠性。輸出插件可以通過記憶卡或者是閃存卡配置緩存數據,所以當數據傳輸發生錯誤時,它不會丟失。緩沖邏輯高度可調,并且可以為客戶定制各種容量以及延遲需求。
舉例:Apache日志歸檔入S3
Fluentd的功能概述,讓我們深入一個例子。下面將會展示怎樣設置Fluentd來實現Apache網絡服務器日志歸檔于S3。
第一步:運行Fluentd
在Ruby的gem界面打開Fluentd (gem install fluentd)。也可以從Treasure Data中找到相關的td-agent。現在,我們運行td-agent,Kiyoto假設在Ubuntu Precise界面(12.04)。td-agent同樣適用于Ubuntu Lucid和CentOS 5/6,以及即將發行的Ubuntu Trusty。
運行以下指令:
curl -L <a >http://toolbelt.treasuredata.com/sh/install-ubuntu-precise.sh</a> | sh
用戶通過以下指令可以檢查td-agent是否安裝成功。
$ which td-agent /usr/sbin/td-agent
第二步:配置輸入和輸出
對于td-agent,該配置文件位于/etc/td-agent/td-agent.conf。再次配置,跟蹤Apache日志文件。
<source> type tail format apache2 path /var/log/apache2/access_log pos_file /var/log/td-agent/apache2.access_log.pos tag s3.apache.access </source>這個片段配置Apache日志文件輸入。Fluentd跟蹤日志文件放置在/var/log/apache2/access_log,根據Apache組合日志形式解析,并且作標記s3.apache.access。
下面,我們配置S3輸出,如下:
<match s3.*.*> type s3 s3_bucket YOUR_BUCKET_NAME path logs/ buffer_path /var/log/td-agent/s3 time_slice_format %Y%m%d%H time_slice_wait 10m utc format_json true include_time_key true include_tag_key true buffer_chunk_limit 256m </match>
<match s3.*.*>告訴Fluentd與以下標記相匹配1)三部分2)以S3為開頭。所有來自Apache進入日志的事件都有s3.apache.access標記,它們在這里相配,然后輸送入S3。
最后,讓我們在更新配置上開始td-agent
$ sudo service td-agent start * Starting td-agent td-agent [OK]
你的數據中也許需要10分鐘才會在S3中顯示,這意味數據需要緩沖(參照"time_slice_wait")。但是,最終日志會在YOUR_BUCKET_NAME/logs/yyyyMMddHH中顯示。同樣的,要確保Fluentd有編寫程序進入S3集。以下是IAM的設置。
{
"Effect": "Allow",
"Action": [
"s3:Get*", "s3:List*","s3:Put*", "s3:Post*"
],
"Resource": [
"arn:aws:s3:::YOUR_BUCKET_NAME/logs/*", "arn:aws:s3::: YOUR_BUCKET_NAME"
]
}
上面的概述和例子只是Fluentd與AWS結合的使用的冰山一角,用戶可以通過更多的資訊了解更多關于AWS的相關信息。
原文鏈接:http://aws.amazon.com/cn/blogs/aws/all-your-data-fluentd/
如您需要了解AWS最新資訊或是技術文檔可訪問AWS中文技術社區;如您有更多的疑問請在AWS技術論壇提出,稍后會有專家進行答疑。
 訂閱“AWS中文技術社區”微信公眾號,實時掌握AWS技術及產品消息!
訂閱“AWS中文技術社區”微信公眾號,實時掌握AWS技術及產品消息!
AWS中文技術社區為廣大開發者提供了一個Amazon Web Service技術交流平臺,推送AWS最新資訊、技術視頻、技術文檔、精彩技術博文等相關精彩內容,更有AWS社區專家與您直接溝通交流!快加入AWS中文技術社區,更快更好的了解AWS云計算技術。
如您需要了解AWS最新資訊或是技術文檔可訪問AWS中文技術社區;如您有更多的疑問請在AWS技術論壇提出,稍后會有專家進行答疑。
(譯者/李雪 責編/王玉平)

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


