
本文利用WebCollector內核的解析,來描述如何設計一個網絡爬蟲。我們先來看看兩個非常優秀爬蟲的設計。
Nutch由apache開源組織提供,主頁:http://nutch.apache.org/
Nutch是目前最好的網絡爬蟲之一,Nutch分為內核和插件兩個模塊組成,內核控制整個爬取的邏輯,插件負責完成每個細節(與流程無關的細節)的實現。具體分工如下:
內核:控制爬蟲按照 Inject -> Generator -> Fetch -> Parse -> Updatedb ( -> 提交索引(可選))的流程進行,而且這些流程都是利用map reduce在hadoop上實現的。
插件:實現爬蟲的http請求、解析器、URL過濾器、索引等細節功能。
Nutch的內核提供了穩定的可在集群上運行的爬取機制(廣度遍歷),插件為爬蟲提供了強大的擴展能力。
Crawler4j由Yasser Ganjisaffar(微軟bing的一位工程師)提供,項目主頁:https://code.google.com/p/crawler4j/
用Crawler4j寫爬蟲,用戶只需要指定兩處:
1) 爬蟲的種子、線程數等配置
2)覆蓋WebCrawler類的visit(Page page)方法,對每個頁面的自定義操作(抽取、存儲)
Nutch是被設計在hadoop上的,而且插件的調度以反射的形式實現,所以它的插件機制,并不如想象的那樣靈活。寫一個插件需要附帶幾個配置文件,并修改Nutch總配置文件。而且Nutch其實是為了搜索引擎定制的,所以NUTCH提供的掛載點,并不能做精抽取之類的業務提供很好的擴展。
Crwler4j雖然提供精簡的用戶接口,但是并沒有一套插件機制,來定制自己的爬蟲。例如用Crawler4j來爬取新浪微博,就需要修改源碼,來完成對新浪微博的模擬登陸。
主頁:https://github.com/CrawlScript/WebCollector
WebCollector使用了Nutch的爬取邏輯(分層廣度遍歷),Crawler4j的的用戶接口(覆蓋visit方法,定義用戶操作),以及一套自己的插件機制,設計了一套爬蟲內核。
WebCollector內核構架圖:
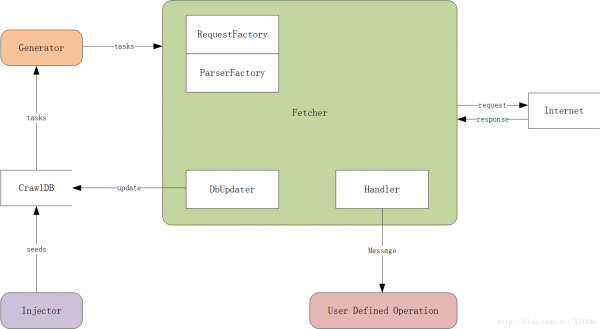
CrawlDB: 任務數據庫,爬蟲的爬取任務(類似URL列表)是存放在CrawlDB中的,CrawlDB根據DbUpdater和Generator所選插件不同,可以有多種形式,如文件、redis、mysql、mongodb等。
Injector: 種子注入器,負責第一輪爬取時,向CrawlDB中提交爬取任務。在斷點續爬的時候,不需要通過Injector向CrawlDB注入種子,因為CrawlDB中已有爬取任務。
Generator: 任務生成器,任務生成器從CrawlDB獲取爬取任務,并進行過濾(正則、爬取間隔等),將任務提交給抓取器。
Fetcher: 抓取器,Fetcher是爬蟲最核心的模塊,Fetcher負責從Generator中獲取爬取任務,用線程池來執行爬取任務,并對爬取的網頁進行鏈接解析,將鏈接信息更新到CrawlDB中,作為下一輪的爬取任務。在網頁被爬取成功/失敗的時候,Fetcher會將網頁和相關信息以消息的形式,發送到Handler的用戶自定義模塊,讓用戶自己處理網頁內容(抽取、存儲)。
DbUpdater: 任務更新器,用來更新任務的狀態和加入新的任務,網頁爬取成功后需要更新CrawlDB中的狀態,對網頁做解析,發現新的連接,也需要更新CrawlDB。
Handler: 消息發送/處理器,Fetcher利用Handler把網頁信息打包,發送到用戶自定義操作模塊。
User Defined Operation: 用戶自定義的對網頁信息進行處理的模塊,例如網頁抽取、存儲。爬蟲二次開發主要就是自定義User Defined Operation這個模塊。實際上User Defined Operation也是在Handler里定義的。
RequestFactory: Http請求生成器,通過RequestFactory來選擇不同的插件,來生成Http請求,例如可以通過httpclient插件來使用httpclient作為爬蟲的http請求,或者來使用可模擬登陸新浪微博的插件,來發送爬取新浪微博的http請求。
ParserFactory: 用來選擇不同的鏈接分析器(插件)。爬蟲之所以可以從一個網頁開始,向多個網頁不斷地爬取,就是因為它在不斷的解析已知網頁中的鏈接,來發現新的未知網頁,然后對新的網頁進行同樣的操作。
爬取邏輯:
WebCollector和Nutch一樣,把爬蟲的廣度遍歷拆分成了分層的操作。
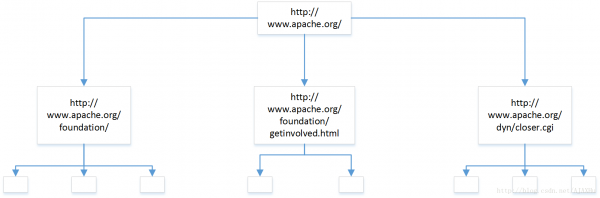
第一層:爬取一個網頁,http://www.apache.org/,解析網頁,獲取3個鏈接,將3個鏈接保存到CrawlDB中,設置狀態為未爬取。同時將http://www.apache.org/的爬取狀態設置為已爬取。結束第一輪。
第二層,找到CrawlDB中狀態為未爬取的頁面(第一層解析出來的3個鏈接),分別爬取,并解析網頁,一共獲得8個鏈接。和第一層操作一樣,將解析出的鏈接放入CrawlDB,設置為未爬取,并將第二層爬取的三個頁面,狀態設置為已爬取。
第三層,找到CrawlDB中狀態為未爬取的頁面(第二層解析出來的8個鏈接).................
每一層都可以作為一個獨立的任務去運行,所以可以將一個大型的廣度遍歷任務,拆分成一個一個小任務。爬蟲里有個參數,設置爬取的層數,指的就是這個。
插件機制:
框架圖中的 Injector、Generator、Request(由RequestFactory生成)、Parser(由ParserFactory生成)、DbUpdater、Response都是以插件實現的。制作插件往往只需要自定義一個實現相關接口的類,并在相關Factory內指定即可。
WebCollector內置了一套插件(cn.edu.hfut.dmic.webcollector.plugin.redis)。基于這套插件,可以把WebCollector的任務管理放到redis數據庫上,這使得WebCollector可以爬取海量的數據(上億級別)。
用戶自定義操作:
對于用戶來說,關注的更多的不是爬蟲的爬取流程,而是對每個網頁要進行什么樣的操作。對網頁進行抽取、保存還是其他操作,應該是由用戶自定義的。
假設我們有個需求,要爬取《知乎》上的所有提問。對用戶來說,只需要定義對知乎的提問如何抽取。
覆蓋BreadthCrawler類的visit方法,即可實現用戶自定義操作,完全不用考慮爬蟲的爬取邏輯。
WebCollector的設計主要來自于Nutch,相當于將Nutch抽象成了一個爬蟲內核。
最后再次附上項目地址:https://github.com/CrawlScript/WebCollector

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


