
【編者按】多線程是程序員面試時常常會面對的問題,對多線程概念的掌握和理解水平,也常常被用來衡量一個人的編程實力。不錯,普通的多線程已經不容易了,那么當多線程碰到“大象”又會產生什么樣的火花?這里我們為大家分享上海創行科技技術總監嚴瀾的博文――Java線程池管理及分布式Hadoop調度框架搭建。
CSDN推薦:歡迎免費訂閱《Hadoop與大數據周刊》獲取更多Hadoop技術文獻、大數據技術分析、企業實戰經驗,生態圈發展趨勢。
以下為原文:
平時的開發中線程是個少不了的東西,比如tomcat里的servlet就是線程,沒有線程我們如何提供多用戶訪問呢?不過很多剛開始接觸線程的開發工程師卻在這個上面吃了不少苦頭。怎么做一套簡便的線程開發模式框架讓大家從單線程開發快速轉入多線程開發,這確實是個比較難搞的工程。
那具體什么是線程呢?首先看看進程是什么,進程就是系統中執行的一個程序,這個程序可以使用內存、處理器、文件系統等相關資源。例如QQ軟件、Eclipse、Tomcat等就是一個exe程序,運行啟動起來就是一個進程。為什么需要多線程?如果每個進程都是單獨處理一件事情不能多個任務同時處理,比如我們打開qq只能和一個人聊天,我們用eclipse開發代碼的時候不能編譯代碼,我們請求tomcat服務時只能服務一個用戶請求,那我想我們還在原始社會。多線程的目的就是讓一個進程能夠同時處理多件事情或者請求。比如現在我們使用的QQ軟件可以同時和多個人聊天,我們用eclipse開發代碼時還可以編譯代碼,tomcat可以同時服務多個用戶請求。
線程這么多好處,怎么把單進程程序變成多線程程序呢?不同的語言有不同的實現,這里說下java語言的實現多線程的兩種方式:擴展java.lang.Thread類、實現java.lang.Runnable接口。
先看個例子,假設有100個數據需要分發并且計算。看下單線程的處理速度:
package thread;
import java.util.Vector;
public class OneMain {
public static void main(String[] args) throws InterruptedException {
Vector<Integer> list = new Vector<Integer>(100);
for (int i = 0; i < 100; i++) {
list.add(i);
}
long start = System.currentTimeMillis();
while (list.size() > 0) {
int val = list.remove(0);
Thread. sleep(100);//模擬處理
System. out.println(val);
}
long end = System.currentTimeMillis();
System. out.println("消耗 " + (end - start) + " ms");
}
// 消耗 10063 ms
}再看一下多線程的處理速度,采用了10個線程分別處理:
package thread;
import java.util.Vector;
import java.util.concurrent.CountDownLatch;
public class MultiThread extends Thread {
static Vector<Integer> list = new Vector<Integer>(100);
static CountDownLatch count = new CountDownLatch(10);
public void run() {
while (list.size() > 0) {
try {
int val = list.remove(0);
System.out.println(val);
Thread.sleep(100);//模擬處理
} catch (Exception e) {
// 可能數組越界,這個地方只是為了說明問題,忽略錯誤
}
}
count.countDown(); // 刪除成功減一
}
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 100; i++) {
list.add(i);
}
long start = System.currentTimeMillis();
for (int i = 0; i < 10; i++) {
new MultiThread().start();
}
count.await();
long end = System.currentTimeMillis();
System.out.println("消耗 " + (end - start) + " ms");
}
// 消耗 1001 ms
}
大家看到了線程的好處了吧!單線程需要10S,10個線程只需要1S。充分利用了系統資源實現并行計算。也許這里會產生一個誤解,是不是增加的線程個數越多效率越高。線程越多處理性能越高這個是錯誤的,范式都要合適,過了就不好了。需要普及一下計算機硬件的一些知識。我們的cpu是個運算器,線程執行就需要這個運算器來運行。不過這個資源只有一個,大家就會爭搶。一般通過以下幾種算法實現爭搶cpu的調度:
這三種算法都有優缺點,實際操作系統是結合多種算法,保證優先級的能夠先處理,但是也不能一直處理優先級的任務。硬件方面為了提高效率也有多核cpu、多線程cpu等解決方案。目前看得出來線程增多了會帶來cpu調度的負載增加,cpu需要調度大量的線程,包括創建線程、銷毀線程、線程是否需要換出cpu、是否需要分配到cpu。這些都是需要消耗系統資源的,由此,我們需要一個機制來統一管理這一堆線程資源。線程池的理念提出解決了頻繁創建、銷毀線程的代價。線程池指預先創建好一定大小的線程等待隨時服務用戶的任務處理,不必等到用戶需要的時候再去創建。特別是在java開發中,盡量減少垃圾回收機制的消耗就要減少對象的頻繁創建和銷毀。
之前我們都是自己實現的線程池,不過隨之jdk1.5的推出,jdk自帶了java.util.concurrent并發開發框架,解決了我們大部分線程池框架的重復工作。可以使用Executors來建立線程池,列出以下大概的,后面再介紹。
有了線程池后有以下幾個問題需要考慮:
考慮到這幾點,我們需要把線程集中管理起來,用java.util.concurrent是做不到的。需要做以下幾點:
組件圖為:
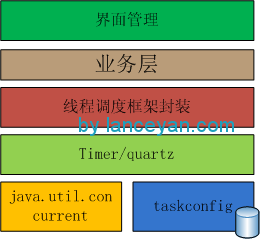
構建好線程調度框架是不是就可以應對大量計算的需求了呢?答案是否定的。因為一個機器的資源是有限的,上面也提到了cpu是時間周期的,任務一多了也會排隊,就算增加cpu,一個機器能承載的cpu也是有限的。所以需要把整個線程池框架做成分布式的任務調度框架才能應對橫向擴展,比如一個機器上的資源達到瓶頸了,馬上增加一臺機器部署調度框架和業務就可以增加計算能力了。好了,如何搭建?如下圖:
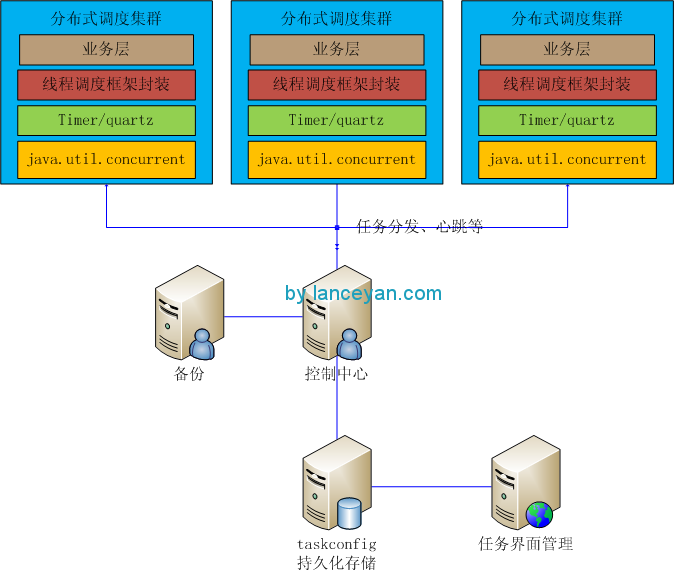
基于jeeframework我們封裝spring、ibatis、數據庫等操作,并且可以調用業務方法完成業務處理。主要組件為:
一般這個架構可以應對常用的分布式處理需求了,不過有個缺陷就是隨著開發人員的增多和業務模型的增多,單線程的編程模型也會變得復雜。比如需要對1000w數據進行分詞,如果這個放到一個線程里來執行,不算計算時間消耗光是查詢數據庫就需要耗費不少時間。有人說,那我把1000w數據打散放到不同機器去運算,然后再合并不就行了嗎?因為這是個特例的模式,專為了這個需求去開發相應的程序沒有問題,但是以后又有其他的海量需求如何辦?比如把倒退3年的所有用戶發的帖子中發帖子最多的粉絲轉發的最高的用戶作息時間取出來。又得編一套程序實現,太麻煩!分布式云計算架構要解決的就是這些問題,減少開發復雜度并且要高性能,大家會不會想到一個最近很熱的一個框架,hadoop,沒錯就是這個玩意。hadoop解決的就是這個問題,把大的計算任務分解、計算、合并,這不就是我們要的東西嗎?不過玩過這個的人都知道他是一個單獨的進程。不是!他是一堆進程,怎么和我們的調度框架結合起來?看圖說話:
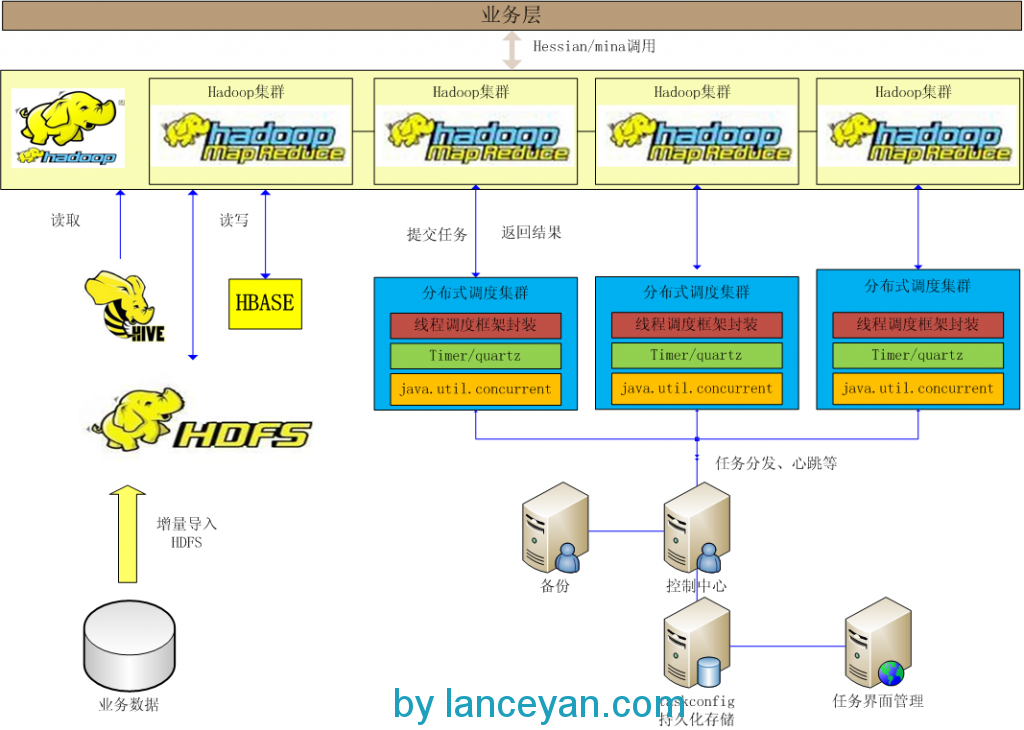
基本前面的分布式調度框架組件不變,增加如下組件和功能:
這樣,整個改造基本完成。不過需要注意的是架構設計一定要減少開發程序的復雜度。這里雖然引入了hadoop模型,但是框架上開發者還是隱藏的。業務處理類既可以在單機模式下運行也可以在hadoop上運行,并且可以調用spring、ibatis。減少了開發的學習成本,在實戰中慢慢體會就學會了 一項新技能。
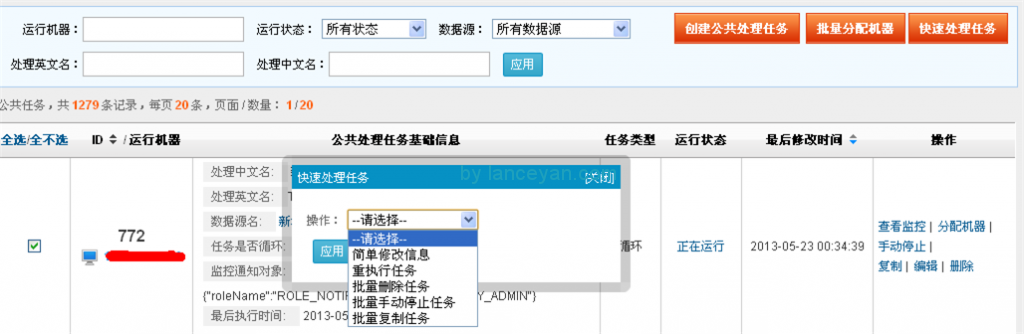
界面截圖:
原文鏈接:JAVA線程池管理及分布式HADOOP調度框架搭建(責編/仲浩)
以“
云計算大數據 推動智慧中國 ”為主題的
第六屆中國云計算大會 將于5月20-23日在北京國家會議中心隆重舉辦。產業觀察、技術培訓、主題論壇、行業研討,內容豐富,干貨十足。票價折扣還剩最后5天,過后將恢復原價,需要購買的朋友,請抓住這最后的機會,點擊報名!

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


