
編者按:為Hadoop的存儲(chǔ)層增加對(duì)OpenStack Swift的支持后,即可直接使用Hadoop MapReduce及其相關(guān)工具直接分析存儲(chǔ)在Swift中的數(shù)據(jù)。本文探討了通過(guò)編寫(xiě) Swift 適配器,將 OpenStack Swift 對(duì)象存儲(chǔ)作為 Hadoop 的底層存儲(chǔ),為 Hadoop 的存儲(chǔ)層增加對(duì) OpenStack Swift 的支持,最終達(dá)到功能驗(yàn)證(Functional POC)的目標(biāo)。以下為原文:
在 Hadoop 中有一個(gè)抽象文件系統(tǒng)的概念,它有多個(gè)不同的子類(lèi)實(shí)現(xiàn),由 DistributedFileSystem 類(lèi)代表的 HDFS 便是其中之一。在 Hadoop 的 1.x 版本中,HDFS 存在 NameNode 單點(diǎn)故障,并且它是為大文件的流式數(shù)據(jù)訪問(wèn)而設(shè)計(jì)的,不適合隨機(jī)讀寫(xiě)大量的小文件。本文將探討通過(guò)使用其他的存儲(chǔ)系統(tǒng),例如 OpenStack Swift 對(duì)象存儲(chǔ),作為 Hadoop 的底層存儲(chǔ),為 Hadoop 的存儲(chǔ)層增加對(duì) OpenStack Swift 的支持,并給出測(cè)試結(jié)果,最終達(dá)到功能驗(yàn)證(Functional POC)的目標(biāo)。值得一提的是,為 Hadoop 增加對(duì) OpenStack Swift 的支持并非要取代 HDFS,而是為使用 Hadoop MapReduce 及其相關(guān)的工具直接分析存儲(chǔ)在 Swift 中的數(shù)據(jù)提供了方便;本文作為一個(gè)階段性的嘗試,目前尚未考慮數(shù)據(jù)局部性(Data Locality),這部分將作為未來(lái)的工作。另外,Hadoop 2.x 提供了高可用 HDFS 的解決辦法,不在本文的討論范圍之內(nèi)。
本文面向的讀者為對(duì) Hadoop 和 OpenStack Swift 感興趣的軟件開(kāi)發(fā)者和管理員,并假設(shè)讀者已經(jīng)對(duì)它們有基本的了解。本文使用的 Hadoop 的版本為 1.0.4,OpenStack Swift 的版本為 1.7.4,Swift Java Client API 的版本為 1.8,用于認(rèn)證的 Swauth 的版本為 1.0.4。
設(shè)想以下情形,如果已經(jīng)在 Swift 中存儲(chǔ)了大量數(shù)據(jù),但是想要使用 Hadoop 對(duì)這些數(shù)據(jù)進(jìn)行分析,挖掘出有用的信息。此時(shí)可能的做法是,先將 Swift 集群中的數(shù)據(jù)導(dǎo)出到中間服務(wù)器,再將這些數(shù)據(jù)導(dǎo)入到 HDFS 中,才能通過(guò)運(yùn)行 MapReduce 作業(yè)來(lái)分析這些數(shù)據(jù)。如果數(shù)據(jù)量非常大,那么整個(gè)導(dǎo)入數(shù)據(jù)的過(guò)程會(huì)很長(zhǎng),并且要使用更多的存儲(chǔ)空間。
如果能將 Hadoop 和 OpenStack Swift 進(jìn)行整合,使得 Hadoop 能夠直接訪問(wèn) Swift 對(duì)象存儲(chǔ),并能運(yùn)行 MapReduce 作業(yè)來(lái)分析存儲(chǔ)在 Swift 中的數(shù)據(jù),那么將提高效率,減少硬件成本。
org.apache.hadoop.fs.FileSystem 是 Hadoop 中的一個(gè)通用文件系統(tǒng)的抽象基類(lèi),它抽象出了文件系統(tǒng)對(duì)文件和目錄的各種操作,例如:創(chuàng)建、拷貝、移動(dòng)、重命名、刪除文件和目錄、讀寫(xiě)文件、讀寫(xiě)文件元數(shù)據(jù)等基本的文件系統(tǒng)操作,以及文件系統(tǒng)的一些其他通用操作。 Hadoop官方API中可以看到FileSystem抽象類(lèi)中的方法和含義。
FileSystem 抽象類(lèi)有多個(gè)不同的子類(lèi)實(shí)現(xiàn),包括:本地文件系統(tǒng)實(shí)現(xiàn)、分布式文件系統(tǒng)實(shí)現(xiàn)、內(nèi)存文件系統(tǒng)實(shí)現(xiàn)、FTP 文件系統(tǒng)實(shí)現(xiàn)、非 Apache 提供的第三方存儲(chǔ)系統(tǒng)實(shí)現(xiàn),以及通過(guò) HTTP 和 HTTPS 協(xié)議訪問(wèn)分布式文件系統(tǒng)的實(shí)現(xiàn)。其中,LocalFileSystem 類(lèi)代表了進(jìn)行客戶(hù)端校驗(yàn)和的本地文件系統(tǒng),在未對(duì) Hadoop 進(jìn)行配置時(shí)是默認(rèn)的文件系統(tǒng)。分布式文件系統(tǒng)實(shí)現(xiàn)是 DistributedFileSystem 類(lèi),即 HDFS,用來(lái)存儲(chǔ)海量數(shù)據(jù),典型的應(yīng)用是存儲(chǔ)大小超過(guò)了單臺(tái)機(jī)器的磁盤(pán)總?cè)萘康拇髷?shù)據(jù)集。第三方存儲(chǔ)系統(tǒng)實(shí)現(xiàn)是由非 Apache 的其他廠商提供的開(kāi)源實(shí)現(xiàn),如 S3FileSystem 和 NativeS3FileSystem 類(lèi),它們是使用 Amazon S3 作為底層存儲(chǔ)的文件系統(tǒng)實(shí)現(xiàn)。
FileSystem 抽象類(lèi)有多個(gè)不同的子類(lèi)實(shí)現(xiàn),包括:本地文件系統(tǒng)實(shí)現(xiàn)、分布式文件系統(tǒng)實(shí)現(xiàn)、內(nèi)存文件系統(tǒng)實(shí)現(xiàn)、FTP 文件系統(tǒng)實(shí)現(xiàn)、非 Apache 提供的第三方存儲(chǔ)系統(tǒng)實(shí)現(xiàn),以及通過(guò) HTTP 和 HTTPS 協(xié)議訪問(wèn)分布式文件系統(tǒng)的實(shí)現(xiàn)。其中,LocalFileSystem 類(lèi)代表了進(jìn)行客戶(hù)端校驗(yàn)和的本地文件系統(tǒng),在未對(duì) Hadoop 進(jìn)行配置時(shí)是默認(rèn)的文件系統(tǒng)。分布式文件系統(tǒng)實(shí)現(xiàn)是 DistributedFileSystem 類(lèi),即 HDFS,用來(lái)存儲(chǔ)海量數(shù)據(jù),典型的應(yīng)用是存儲(chǔ)大小超過(guò)了單臺(tái)機(jī)器的磁盤(pán)總?cè)萘康拇髷?shù)據(jù)集。第三方存儲(chǔ)系統(tǒng)實(shí)現(xiàn)是由非 Apache 的其他廠商提供的開(kāi)源實(shí)現(xiàn),如 S3FileSystem 和 NativeS3FileSystem 類(lèi),它們是使用 Amazon S3 作為底層存儲(chǔ)的文件系統(tǒng)實(shí)現(xiàn)。
通過(guò)閱讀 Hadoop 的文件系統(tǒng)相關(guān)的源代碼和 Javadoc,并借助于工具,可以分析出 FileSystem 抽象類(lèi)的各個(gè)抽象方法的含義和用法,以及 FileSystem API 中各類(lèi)之間的繼承、依賴(lài)關(guān)系。org.apache.hadoop.fs 包中包括了 Hadoop 文件系統(tǒng)相關(guān)的接口和類(lèi),如文件輸入流 FSDataInputStream 類(lèi)和輸出流 FSDataOutputStream 類(lèi),文件元數(shù)據(jù) FileStatus 類(lèi),所有的輸入/輸出流類(lèi)都分別和 FSDataInputStream 類(lèi)和 FSDataOutputStream 類(lèi)是組合關(guān)系,所有的文件系統(tǒng)子類(lèi)實(shí)現(xiàn)均繼承自 FileSystem 抽象類(lèi)。Hadoop FileSystem API 的類(lèi)圖如下圖所示。
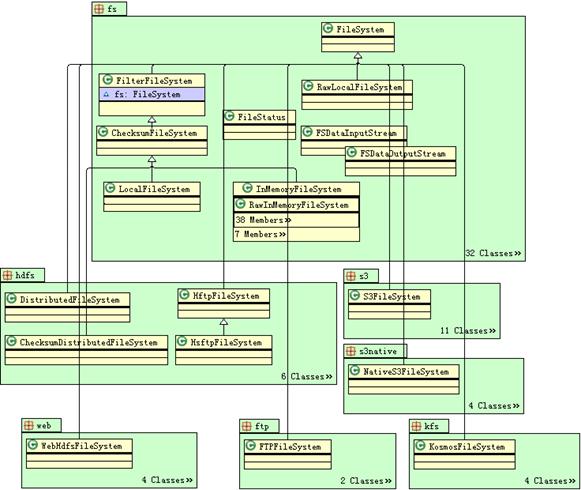
Hadoop FileSystem API 的類(lèi)圖
以 S3FileSystem 為例,它使用的底層存儲(chǔ)系統(tǒng)是 Amazon S3,繼承了 FileSystem 抽象類(lèi),是它的一個(gè)具體實(shí)現(xiàn),并實(shí)現(xiàn)了針對(duì) Amazon S3 的輸入/輸出流。用戶(hù)可以在 Hadoop 的配置文件 core-site.xml 中為 fs.default.name 屬性指定 Amazon S3 存儲(chǔ)系統(tǒng)的 URI,就可以使 Hadoop 得以訪問(wèn) Amazon S3,并在其上運(yùn)行 MapReduce 作業(yè)。
Swift 通過(guò) HTTP 協(xié)議對(duì)外提供存儲(chǔ)服務(wù),有一個(gè) REST 風(fēng)格的 API。Swift 本身是用 Python 語(yǔ)言實(shí)現(xiàn)的,但是也提供了多種編程語(yǔ)言的客戶(hù)端 API,例如:Python、Java、PHP、C#、Ruby 等。這些客戶(hù)端 API 都通過(guò)發(fā)起 HTTP 請(qǐng)求和接收 HTTP 響應(yīng)來(lái)與 Swift 集群的代理節(jié)點(diǎn)進(jìn)行交互,Swift 客戶(hù)端 API 在 REST API 之上提供了更高層次的對(duì)容器和對(duì)象的操作,使得程序員編寫(xiě)訪問(wèn) Swift 的程序變得更為方便。
Swift 的 Java 客戶(hù)端 API 名叫 java-cloudfiles,也是一個(gè)開(kāi)源項(xiàng)目。其中的 FilesClient 類(lèi)提供了對(duì) Swift 對(duì)象存儲(chǔ)的各種操作,包括:登錄 Swift、創(chuàng)建和刪除 Account、容器、對(duì)象,獲得 Account、容器、對(duì)象的元數(shù)據(jù),以及讀寫(xiě)對(duì)象的方法。其他相關(guān)的類(lèi)包括:FilesContainer、FilesObject、FilesContainerInfo、FilesObjectMetaData 等,它們分別代表 Swift 中的容器和對(duì)象以及對(duì)應(yīng)的元數(shù)據(jù),如容器包含的對(duì)象個(gè)數(shù),對(duì)象的大小、修改時(shí)間等。版本號(hào)為 1.8 的 java-cloudfiles 能夠和開(kāi)源版本的 Swift 兼容。Filesclient 類(lèi)中主要的方法和含義見(jiàn)下表。
| 方法簽名 | 含義 |
|---|---|
| FilesClient(String, String, String, String, int) | 構(gòu)造方法,參數(shù)包括代理節(jié)點(diǎn)的 URL、account、username、password,timeout |
| boolean login() | 登錄 Swift |
| void createContainer(String) | 創(chuàng)建容器 |
| boolean deleteContainer(String) | 刪除容器 |
| boolean containerExists (String) | 判斷容器是否存在 |
| boolean storeObject(String, byte[], String, String, Map<String,String>) | 把字節(jié)數(shù)組中的值存儲(chǔ)到對(duì)象中,把元數(shù)據(jù)存儲(chǔ)到擴(kuò)展屬性中 |
| byte[] getObject (String, String) | 從 Swift 獲取對(duì)象內(nèi)容并存入字節(jié)數(shù)組 |
| List<FilesContainer> listContainers() | 列出某個(gè)賬戶(hù)包含的所有容器 |
| List<FilesObject> listObjects(String) | 列出某個(gè)容器包含的所有對(duì)象 |
| FilesContainerInfo getContainerInfo (String) | 獲取容器的元數(shù)據(jù) |
| FilesObjectMetaData getObjectMetaData (String, String) | 獲取對(duì)象的元數(shù)據(jù) |
綜上所述,Hadoop FileSystem API 能夠接受新的文件系統(tǒng)實(shí)現(xiàn)的機(jī)制,以及能夠用 Java 語(yǔ)言編寫(xiě)應(yīng)用程序與 Swift 進(jìn)行交互操作,這兩點(diǎn)使得擴(kuò)展 Hadoop 抽象文件系統(tǒng)是可行的。
由上述內(nèi)容得知,要擴(kuò)展 Hadoop 的抽象文件系統(tǒng),需要做以下兩項(xiàng)工作:繼承并實(shí)現(xiàn) FileSystem 抽象類(lèi),并在實(shí)現(xiàn)類(lèi)中使用 Swift 的 Java 客戶(hù)端 API 以進(jìn)行各種文件操作。因此,擴(kuò)展系統(tǒng)的設(shè)計(jì)應(yīng)遵循軟件設(shè)計(jì)模式當(dāng)中的對(duì)象適配器模式(Adapter Pattern)。對(duì)象適配器模式的作用是進(jìn)行接口適配,就是將一個(gè)類(lèi)的接口轉(zhuǎn)換成客戶(hù)程序希望的另一個(gè)接口,使得原本由于接口不兼容而不能一起工作的那些類(lèi)可以一起工作。
在擴(kuò)展系統(tǒng)中,Swift 適配器調(diào)用 Swift 的 Java 客戶(hù)端 API,實(shí)現(xiàn)了對(duì) Swift 對(duì)象存儲(chǔ)的操作,Hadoop MapReduce API 調(diào)用 Hadoop FileSystem API,對(duì)于 MapReduce 來(lái)說(shuō),底層的 HDFS 和 Swift 都是透明的。與 HDFS 相比,Swift 適配器所在的 API 層次結(jié)構(gòu)如下圖所示。
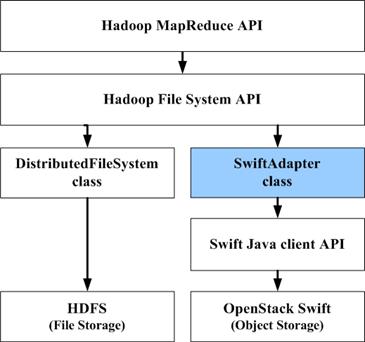
API 層次結(jié)構(gòu)
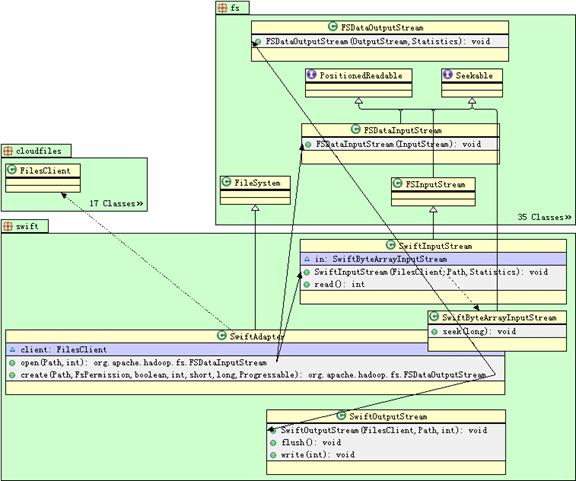
Swift適配器類(lèi)圖
下表為Swift 適配器中類(lèi)的詳細(xì)關(guān)系:
| 類(lèi)名 |
父接口/父類(lèi) |
依賴(lài)類(lèi)
|
| SwiftAdapter
|
FileSystem
|
FilesClient, SwiftInputStream, SwiftOutputStream 等
|
| SwiftInputStream
|
FSInputStream
|
FilesClient, SwiftByteArrayInputStream
|
| SwiftByteArrayInputStream
|
ByteArrayInputStream, Seekable
|
|
| SwiftByteOutputStream
|
ByteArrayOutputStream
|
FilesClient
|
| SwiftFileStatus(SwiftAdapter 的內(nèi)部類(lèi))
|
FileStatus
|
|
在與 Swift 進(jìn)行交互之前需要首先登錄 Swift,因此要使用 Swift 中預(yù)先創(chuàng)建的某個(gè)賬戶(hù)、用戶(hù)名和密碼,實(shí)現(xiàn)的細(xì)節(jié)如下。
調(diào)用 Swift 的 Java 客戶(hù)端 API,實(shí)現(xiàn)針對(duì) Swift 的輸入/輸出流。
在 Hadoop 中,所有的輸入流類(lèi)都需要繼承并實(shí)現(xiàn) FSInputStream 抽象類(lèi),重點(diǎn)是實(shí)現(xiàn) read 方法和 seek 方法。read 方法從輸入流中讀取下一個(gè)字節(jié),是輸入流類(lèi)最基本的方法,seek 方法設(shè)置輸入流的讀取位置,如果使用一個(gè)字節(jié)數(shù)組作為緩沖則能實(shí)現(xiàn)隨機(jī)定位到某一字節(jié)。SwiftByteArrayInputStream 類(lèi)繼承了 ByteArrayInputStream 類(lèi)和 Seekable 接口,它使用了一個(gè)字節(jié)數(shù)組作為緩沖。SwiftInputStream 類(lèi)繼承 FSInputStream 抽象類(lèi),并包含 SwiftByteArrayInputStream 類(lèi)的一個(gè)引用,它調(diào)用 Swift 的 Java 客戶(hù)端 API,將 Swift 中的對(duì)象讀入到字節(jié)數(shù)組的緩沖。通過(guò)這樣的實(shí)現(xiàn),針對(duì) Swift 的輸入流類(lèi) SwiftInputStream 就具有了 read 和 seek 這些輸入流的基本操作。
在 Hadoop 中,輸出流類(lèi)只需要是 OutputStream 抽象類(lèi)的子類(lèi)即可,重點(diǎn)是實(shí)現(xiàn) write 方法和 flush 方法,它可以選擇是否實(shí)現(xiàn) Syncable 接口的 sync 方法,sync 方法使得緩沖的數(shù)據(jù)與底層存儲(chǔ)設(shè)備同步。write 方法向輸出流中寫(xiě)入一個(gè)字節(jié),是輸出流類(lèi)最基本的方法。SwiftOutputStream 類(lèi)繼承了 OutputStream 抽象類(lèi)的子類(lèi) ByteArrayOutputStream,在 flush 方法中調(diào)用 Swift 的 Java 客戶(hù)端 API,將緩沖中的所有字節(jié)存儲(chǔ)到 Swift 中的對(duì)象。通過(guò)這樣的實(shí)現(xiàn),針對(duì) Swift 的輸出流類(lèi) SwiftOutputStream 就具有了 write 和 flush 這些輸出流的基本操作。
調(diào)用 Swift 的 Java 客戶(hù)端 API,實(shí)現(xiàn) SwiftAdapter 的各種文件操作。
實(shí)現(xiàn)的操作包括:打開(kāi)文件并返回輸入流,創(chuàng)建文件并返回輸出流,刪除路徑,判斷路徑是否存在,獲得路徑的元數(shù)據(jù),獲得文件系統(tǒng)的 URI,獲得工作目錄,創(chuàng)建目錄等等。目錄對(duì)應(yīng) Swift 中的容器,文件對(duì)應(yīng) Swift 中的對(duì)象。在實(shí)現(xiàn)的過(guò)程中,有幾個(gè)問(wèn)題需要進(jìn)行特殊處理。
首先,由于在 Swift 對(duì)象存儲(chǔ)中,名稱(chēng)空間是扁平的,沒(méi)有目錄層次結(jié)構(gòu),所以在路徑上需要進(jìn)行特殊處理,具體的做法是允許文件名稱(chēng)包含斜杠(/)。在一般的 POSIX 兼容的文件系統(tǒng)中,斜杠不能作為文件名的一部分,屬于非法字符,而在 Swift 中是允許的。通過(guò)這種方式,可以實(shí)現(xiàn)虛擬的目錄層次結(jié)構(gòu)。此時(shí),根路徑作為容器的名稱(chēng),根目錄之后的整個(gè)路徑都作為對(duì)象的名稱(chēng)。
其次,由于 Swift 對(duì)象存儲(chǔ)不是一個(gè)真正的文件系統(tǒng),與一般的文件系統(tǒng)不同,不包含用戶(hù)、用戶(hù)組以及其他使用者的可讀、可寫(xiě)、可執(zhí)行的權(quán)限信息,所以在權(quán)限上需要進(jìn)行特殊處理,具體的做法是將這些權(quán)限信息存儲(chǔ)在對(duì)象的擴(kuò)展屬性中。FilesClient 類(lèi)的 storeObject 方法有一個(gè) java.util.Map 類(lèi)型的參數(shù),可以把用戶(hù)、用戶(hù)組以及其他使用者的權(quán)限信息作為 java.util.Map 對(duì)象中的元素,以代表權(quán)限類(lèi)型的字符串作為鍵,以權(quán)限對(duì)應(yīng)的數(shù)字作為值,例如用戶(hù)、用戶(hù)組以及其他使用者的權(quán)限信息分別為<"Acl-User", "6">、<"Acl-Group", "4">、<"Acl-Others", "4">。把包含權(quán)限信息的 java.util.Map 對(duì)象作為參數(shù)傳遞給 storeObject 方法,就可以將權(quán)限信息存儲(chǔ)到擴(kuò)展屬性中了。
SwiftAdapter 類(lèi)中接口轉(zhuǎn)換的對(duì)應(yīng)關(guān)系如表 4 所示,下表列出了 SwiftAdapter 類(lèi)與 FilesClient 類(lèi)的方法之間的對(duì)應(yīng)關(guān)系。
| SwiftAdapter 類(lèi)的方法 | FilesClient 類(lèi)被轉(zhuǎn)換的方法 |
|---|---|
| initialize | 調(diào)用 FilesClient 類(lèi)的構(gòu)造方法,初始化 FilesClient 類(lèi)的實(shí)例 |
| open | getObject 返回的字節(jié)數(shù)組作為 SwiftInputStream 中的緩沖存儲(chǔ) |
| create | storeObject 將 SwiftOutputStream 中緩沖存儲(chǔ)中的字節(jié)保存到 Swift 的對(duì)象中 |
| append | 不支持此操作 |
| rename | deleteObject, storeObject |
| delete | 目錄對(duì)應(yīng) deleteObject 和 deleteContainer,文件對(duì)應(yīng) deleteObject |
| mkdirs | createContainer,storeObject |
| getFileStatus | 目錄對(duì)應(yīng) getContainerInfo, 文件對(duì)應(yīng) getObjectMetaData |
| initialize | 調(diào)用 FilesClient 類(lèi)的構(gòu)造方法,初始化 FilesClient 類(lèi)的實(shí)例 |
| open | getObject 返回的字節(jié)數(shù)組作為 SwiftInputStream 中的緩沖存儲(chǔ) |
| create | storeObject 將 SwiftOutputStream 中緩沖存儲(chǔ)中的字節(jié)保存到 Swift 的對(duì)象中 |
編譯源代碼并打包成 JAR 文件,再將 JAR 文件及其依賴(lài)的類(lèi)庫(kù)部署到 Hadoop 集群中所有節(jié)點(diǎn)的$HADOOP_PREFIX/share/hadoop/lib 目錄中。
使用 RPM 文件安裝的 Hadoop 的類(lèi)庫(kù)默認(rèn)目錄是/usr/share/hadoop/lib。這就像將插件安裝到 Hadoop 中一樣,沒(méi)有對(duì)原有軟件進(jìn)行修改。
修改 Hadoop 集群中所有節(jié)點(diǎn)的配置文件 core-site.xml,使文件系統(tǒng)的 URI 指向 Swift 的代理節(jié)點(diǎn),并指定 Swift 中的某個(gè) Account、用戶(hù)名和密碼。
這些屬性會(huì)被 Swift 適配器讀取。在 Swift 集群中部署多臺(tái)代理節(jié)點(diǎn),還可以使用專(zhuān)門(mén)的負(fù)載均衡器(Load Balancer)或輪轉(zhuǎn) DNS(Round-robin DNS)指向這些代理節(jié)點(diǎn),并在 core-site.xml 中使文件系統(tǒng)的 URI 指向負(fù)載均衡器或輪轉(zhuǎn) DNS。配置文件 core-site.xml 的屬性如下表所示。
| 屬性 | 值 | 說(shuō)明 |
|---|---|---|
| fs.default.name | swift://proxy.swiftcluster.net:8080 | proxy.swiftcluster.net 是預(yù)先設(shè)置的輪轉(zhuǎn) DNS 的域名 |
| fs.swift.impl | swift.SwiftAdapter | 完整的類(lèi)名 |
| fs.swift.account | AUTH_5248434a-4066-407e-b5e3-0bec4fdbfc71 | Swift 中的一個(gè) Account 名稱(chēng) |
| fs.swift.username | test:root | Swift 中的一個(gè)用戶(hù)名 |
| fs.swift.password | testing | 上述用戶(hù)名對(duì)應(yīng)的密碼 |
| fs.swift.auth.url | http://proxy.swiftcluster.net:8080/auth | 認(rèn)證服務(wù)器的 URL,此處使用 Swauth |
配置文件 core-site.xml 的屬性
Hadoop 集群中部署了 1 臺(tái) JobTracker 節(jié)點(diǎn),以及多臺(tái)運(yùn)行 TaskTracker 的 slave 節(jié)點(diǎn),所有節(jié)點(diǎn)均加入了 Swift 適配器 JAR 文件及其依賴(lài)的類(lèi)庫(kù)。Swift 集群中部署了多個(gè) Proxy 節(jié)點(diǎn)和 Storage 節(jié)點(diǎn),并且部署了 1 臺(tái)輪轉(zhuǎn) DNS 服務(wù)器,它指向這些 Swift 集群中的代理節(jié)點(diǎn)。整個(gè)擴(kuò)展系統(tǒng)的拓?fù)浣Y(jié)構(gòu)如下圖所示。
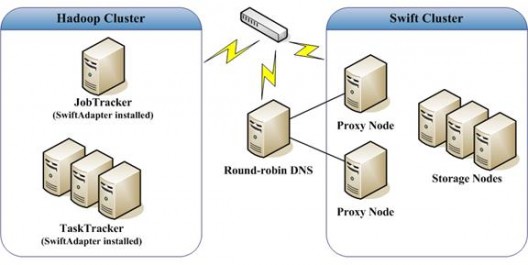
擴(kuò)展系統(tǒng)拓?fù)浣Y(jié)構(gòu)圖
在 Swift 適配器中,以初始化文件系統(tǒng)實(shí)例、打開(kāi)文件并讀取數(shù)據(jù)、以及創(chuàng)建文件并寫(xiě)入數(shù)據(jù)的操作為例,分別敘述它們的流程,并使用 UML 時(shí)序圖展示出來(lái)。
Hadoop 的文件系統(tǒng)客戶(hù)端命令行程序?qū)?yīng)的是 org.apache.hadoop.fs.FsShell 類(lèi)。在使用該命令行程序與文件系統(tǒng)進(jìn)行交互的時(shí)候,Hadoop 首先會(huì)根據(jù)配置文件中指定的 scheme 尋找對(duì)應(yīng)的文件系統(tǒng)實(shí)現(xiàn)類(lèi),并進(jìn)行初始化操作。org.apache.hadoop.fs.FileSystem 類(lèi)有一個(gè)靜態(tài)內(nèi)部類(lèi) FileSystem.Cache,它使用一個(gè) Java 的 Map 類(lèi)型緩存了文件系統(tǒng)的實(shí)例對(duì)象,鍵是文件系統(tǒng)的 scheme 名稱(chēng),例如”hdfs”,值是對(duì)應(yīng)的文件系統(tǒng)對(duì)象實(shí)例,例如 DistributedFileSystem 類(lèi)的實(shí)例。在本文的實(shí)現(xiàn)中,Swift 適配器的 scheme 名稱(chēng)是”swift”,對(duì)應(yīng)的文件系統(tǒng)類(lèi)是 swift.SwiftAdapter,并且在配置文件中設(shè)置屬性 fs.swift.impl 為 swift.SwiftAdapter。初始化文件系統(tǒng)實(shí)例的詳細(xì)流程如下:如果名稱(chēng)為”swift”的 scheme 存在于該緩存中,則 FileSystem.Cache 直接通過(guò) get 方法返回 swift.SwiftAdapter 的對(duì)象實(shí)例。否則,F(xiàn)ileSystem 類(lèi)調(diào)用靜態(tài)方法 createFileSystem,接著調(diào)用 ReflectionUtils 類(lèi)的 newInstance 方法,最終調(diào)用 Constructor 類(lèi)的 newInstance 方法,以反射的方式獲得 Swift 適配器類(lèi)的對(duì)象實(shí)例,最后調(diào)用 initialize 方法進(jìn)行必要的初始化操作。初始化文件系統(tǒng)實(shí)例的 UML 時(shí)序圖如下圖所示。
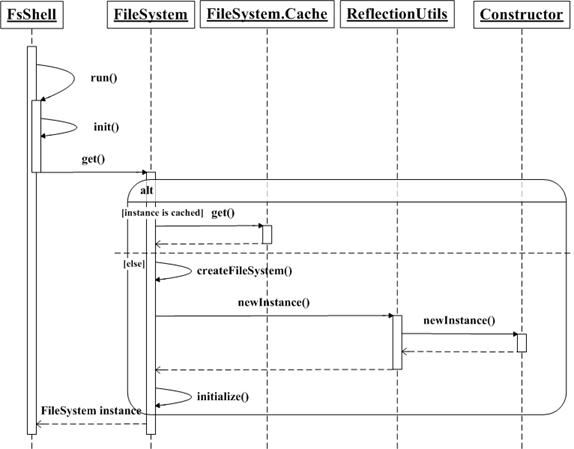
初始化文件系統(tǒng)實(shí)例的 UML 時(shí)序圖
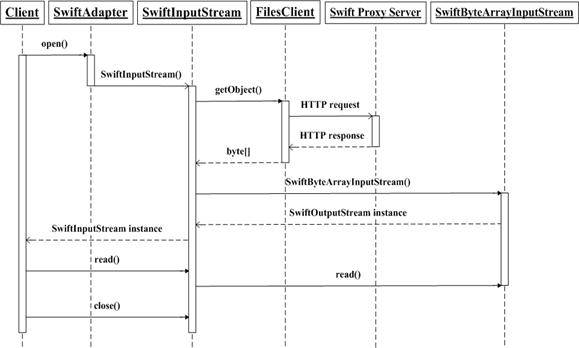
打開(kāi)文件并讀取數(shù)據(jù)的 UML 時(shí)序圖
創(chuàng)建文件并寫(xiě)入數(shù)據(jù)的詳細(xì)流程如下:在創(chuàng)建文件的時(shí)候,客戶(hù)程序調(diào)用 SwiftAdapter 類(lèi)的 create 方法,SwiftAdapter 對(duì)象首先初始化 Swift 輸出流類(lèi) SwiftOutputStream 的實(shí)例,然后客戶(hù)程序調(diào)用 SwiftOutputStream 對(duì)象的 write 方法把數(shù)據(jù)寫(xiě)入到它內(nèi)部的字節(jié)數(shù)組緩沖中,直到調(diào)用它的 flush 方法或 close 方法,SwiftOutputStream 對(duì)象才會(huì)調(diào)用 FilesClient 對(duì)象的 storeObject 方法,向 Swift 集群中的代理服務(wù)器發(fā)起 HTTP 請(qǐng)求將緩沖存儲(chǔ)中的字節(jié)寫(xiě)入 Swift 中的對(duì)象。創(chuàng)建文件并寫(xiě)入數(shù)據(jù)的 UML 時(shí)序圖如下圖所示。
打開(kāi)文件并讀取數(shù)據(jù)的 UML 時(shí)序圖
通過(guò) Swift 適配器,將高可用的 Swift 對(duì)象存儲(chǔ)作為 Hadoop 的底層存儲(chǔ)系統(tǒng),使得 Hadoop 在存儲(chǔ)層面具有了高可用性。把 Swift 適配器部署到已有的 Hadoop 集群中是簡(jiǎn)單快捷的。原本用來(lái)分析存儲(chǔ)在 HDFS 中的數(shù)據(jù)的 MapReduce 應(yīng)用程序,也無(wú)需修改即可分析存儲(chǔ)在 Swift 中的數(shù)據(jù)。
但是,使用 Swift 適配器將 Hadoop 與 Swift 對(duì)象存儲(chǔ)整合之后,整個(gè)系統(tǒng)的缺點(diǎn)是失去了數(shù)據(jù)局部性(Data Locality)的優(yōu)勢(shì)。在 HDFS 中,NameNode 節(jié)點(diǎn)知道每一個(gè)文件塊存儲(chǔ)在哪一個(gè) DataNode 節(jié)點(diǎn)上。因此在運(yùn)行 MapReduce 作業(yè)的過(guò)程中,用戶(hù)編寫(xiě)的 MapReduce 應(yīng)用程序的二進(jìn)制文件會(huì)被 MapReduce 框架調(diào)度發(fā)送至盡可能離數(shù)據(jù)最近的節(jié)點(diǎn),最好的情況是在文件塊所在的 DataNode 節(jié)點(diǎn)上的 TaskTracker 進(jìn)程啟動(dòng) Map 任務(wù),此時(shí) Map 任務(wù)從本地文件系統(tǒng)讀取輸入文件,這樣可以避免大量的數(shù)據(jù)在 Hadoop 集群的不同節(jié)點(diǎn)之間傳輸,節(jié)省了網(wǎng)絡(luò)帶寬,也能加速 MapReduce 作業(yè)在 map 階段的運(yùn)行速度。
通過(guò) Swift 適配器,將 Swift 對(duì)象存儲(chǔ)作為 Hadoop 的底層存儲(chǔ)系統(tǒng),對(duì) Hadoop 集群來(lái)說(shuō),Swift 是一個(gè)外部存儲(chǔ)系統(tǒng),TaskTracker 和文件不在同一個(gè)節(jié)點(diǎn)上,因此在 MapReduce 作業(yè)運(yùn)行的 map 階段,所有的讀取文件操作都通過(guò)網(wǎng)絡(luò)傳輸數(shù)據(jù)。Swift 對(duì)象存儲(chǔ)對(duì)于 Hadoop 集群來(lái)說(shuō)是一個(gè)黑盒,MapReduce 框架無(wú)法知道存儲(chǔ)系統(tǒng)的內(nèi)部細(xì)節(jié)。
本文的目的是為 Hadoop 的存儲(chǔ)層增加對(duì) OpenStack Swift 的支持,并非要取代 HDFS。作為一個(gè)階段性的嘗試,目前并未考慮和解決數(shù)據(jù)局部性的問(wèn)題,這部分將作為未來(lái)的工作。
Swift 適配器使得 Swift 對(duì)象存儲(chǔ)可以作為 Hadoop 的底層存儲(chǔ)系統(tǒng),實(shí)現(xiàn)的效果包括兩個(gè)方面:第一,使用 Hadoop 的文件系統(tǒng)命令行訪問(wèn) Swift 對(duì)象存儲(chǔ)。第二,運(yùn)行 MapReduce 作業(yè)分析存儲(chǔ)在 Swift 中的數(shù)據(jù)。
ls 列出某個(gè)目錄下的文件,在實(shí)現(xiàn)時(shí)未讀取文件的實(shí)際修改時(shí)間,因此默認(rèn)為 1970-1-1。如圖所示。

cat 查看某個(gè)文件的內(nèi)容,如圖所示。

mkdir 創(chuàng)建目錄,如創(chuàng)建成功則無(wú)提示信息,否則提示該目錄已存在的信息,如圖所示。

put 將本地文件存入 Swift 對(duì)象存儲(chǔ)中,如操作成功則無(wú)提示信息,如圖所示。

get 將 Swift 對(duì)象存儲(chǔ)中的對(duì)象存到本地文件中,如操作成功則無(wú)提示信息,如圖所示。

rm, rmr 前者刪除文件,后者級(jí)聯(lián)刪除目錄,操作不論成功與否都有提示信息,如圖所示。

du 顯示某個(gè)目錄下的目錄和文件的大小,即字節(jié)長(zhǎng)度,如圖所示。

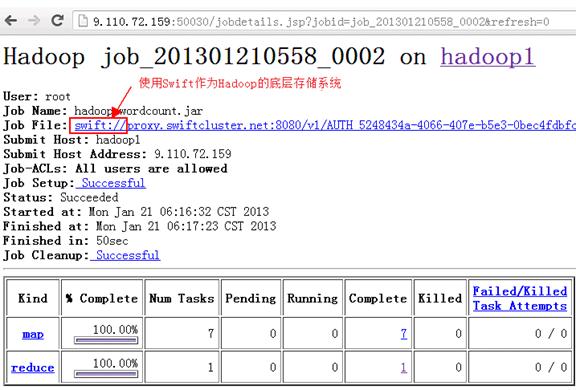
首先在 Hadoop 集群中提交一個(gè) MapReduce 作業(yè),然后通過(guò)如下 URL 訪問(wèn) JobTracker 節(jié)點(diǎn)的 MapReduce 管理的頁(yè)面:http://<jobtracker-ip-address>:50030/jobtracker.jsp,點(diǎn)擊具體的作業(yè)鏈接進(jìn)入查看運(yùn)行結(jié)果的頁(yè)面,從頁(yè)面上的文件 Scheme(swift://)可以看出 Hadoop 已經(jīng)在 Swift 對(duì)象存儲(chǔ)之上運(yùn)行 MapReduce 作業(yè)了,運(yùn)行結(jié)果頁(yè)面如圖 8 所示。
本文分析了 Hadoop FileSystem API 和 Swift Java client API,以及 Hadoop 與 OpenStack Swift 整合的可行性,介紹了 Swift 適配器的設(shè)計(jì)和實(shí)現(xiàn)細(xì)節(jié),最終將 OpenStack Swift 對(duì)象存儲(chǔ)作為 Hadoop 的底層存儲(chǔ),使得它們能夠協(xié)同工作,為 Hadoop 的存儲(chǔ)層增加了對(duì) OpenStack Swift 的支持。
原文鏈接: 為 Hadoop 的存儲(chǔ)層增加對(duì) OpenStack Swift 的支持(責(zé)編:周小璐)
第六屆中國(guó)云計(jì)算大會(huì)(China Cloud Computing Conference)將于2014年05月在國(guó)家會(huì)議中心?北京召開(kāi)。此次會(huì)議繼承了前五屆大會(huì)的成功經(jīng)驗(yàn),將邀請(qǐng)更多國(guó)內(nèi)外知名院士、專(zhuān)家學(xué)者、行業(yè)CIO參加會(huì)議并作演講。

程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學(xué)習(xí),php手冊(cè),CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學(xué)習(xí),原版權(quán)很多不明,如有侵權(quán)請(qǐng)聯(lián)系本站,謝謝!
粵ICP備14040726號(hào)-1?? 2015-2020 程序員人生 版權(quán)所有


