
NoSQL是筆者最早接觸大數據領域的相關知識,因此在大家都在暢談Hadoop、Spark時,筆者仍然保留著NoSQL博文的閱讀習慣。在偶爾閱讀一篇Redis博文過程中,筆者發現了 jacksu的個人博客,并在其中發現了大量的分布式系統操作經驗,從而通過他的引薦了解了QQ成立之初后臺3個基礎團隊之一的QQ運營組,這里我們一起走進。

QQ大數據團隊
CSDN:首先,請介紹一下您的團隊?
聶晶:我們團隊是社交網絡事業群/社交網絡運營部/數據中心/平臺開發二組,前身是QQ成立之初后臺3個基礎團隊之一的QQ運營組。目前團隊成員10人,主要負責社交網絡事業群的基礎數據挖掘系統和產品應用系統的研發和運營。作為騰訊內部較早研究并使用Hadoop的團隊,結合Hadoop、Spark等開源系統,推出面向應用的數據解決方案ADs(Aggregate Data services),涵蓋數據整個生命周期;曾經面向復雜關系鏈計算,研發出圈子分布式計算系統等。目前,興趣在于面向計算的分布式快速應用開發部署系統――R2,以及數據可視化的應用。
CSDN:貴團隊是ADs的作者,可否為我們介紹一下當下ADs在騰訊的使用程度,比如支撐的業務,處理的數據集,集群規模等。
聶晶:ADs是騰訊即時通信線通用的,負責數據收集、分發的基礎設施。ADs是一系列組件的統稱,這些組件絕大多數為自主研發,可以靈活組合起來支持實時和離線的多種數據需求。目前,ADs集群共700臺各型服務器,日處理數據在2300億左右,存儲數據10PB+。為騰訊內部5個部門,20多個業務線提供有效的支撐,比如數據查詢、數據分析、產品統計、數據挖掘和用戶推薦等。像QQ,手機QQ,以及其他通過即時通信工具接入的業務,其基礎數據都經由ADs對外提供服務。
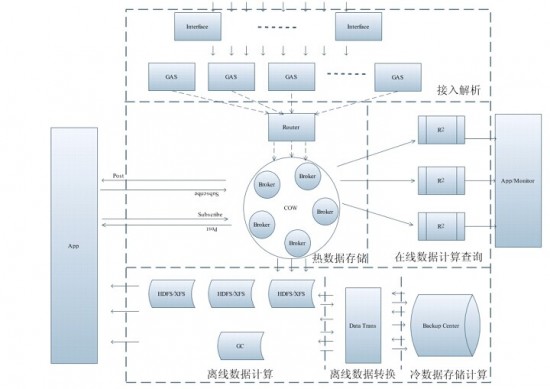
圖一 ADs架構圖
CSDN:眾所周知,擴展性是大型網絡架構中必不可少的一環,請結合騰訊的實踐經驗做一些node rebalance相關分享?
聶晶:擴展性,在我們看來,包含兩種含義:第一種是功能的擴展性,還有一種是整個系統吞吐的擴展性。
對于功能的擴展,從系統層面上,可以做的是根據系統承載的功能,抽象成不同組件,不同組件之間的結合,可以靈活擴展出面對新場景的功能。比如,ADs就抽象出接入自動解析的GAS(General Analyses Service)組件,高吞吐存儲的COW組件,數據轉換的DataT組件。GAS+COW就能提供應用的數據獲取服務;GAS+DataT提供給離線模型計算使用。
對于整個系統的吞吐擴展,一般都會設計成去中心化的結構,每個節點提供對等的服務能力。比如GAS就是如此,每個機器負責的是對等的服務能力,如果機器死機或者闊擴容,通過配置中心更新節點路由,保證服務一致,加上一些消息探測的機制,即使在某些極端情況下沒有更新路由,也不會丟失消息。
CSDN:在線處理環節,你們自主研發了R2,可否分享一下與當下流行計算框架Spark及Storm的對比?
聶晶:首先,R2 跟已有開源項目最大的不同在于它從一開始就是為了面向實時服務而設計的,所以它對性能和低延遲和系統可用性要求更強,比如,在推薦好友業務中,需要在200ms內返回數據,但是涉及處理的數據卻可能高達幾百MB,怎樣提升計算降低延時,是一個挑戰。其次,從架構上看,R2是一個對稱的結構,沒有單點。節點可以做到即插即用,擴容縮容不影響服務,這對存在一定資源空閑的大型機房來說,可以隨時使用空閑資源,節省成本。再次,從功能上講,R2對一些特定的迭代計算做了大量優化,使得很多智能算法的實現變得簡單高效。
CSDN:在ADs中,你們使用Hadoop做離線處理,那么如此規模下,主要的挑戰是什么,會遇到哪些坑,及需要避免的地方?
聶晶:
1. 目前前主要使用的還是1.0版本,由于1.0版本的單點問題,如果主控機器死機,對業務會造成較大的影響。
2. 對模型計算,涉及到大數據的頻繁讀寫計算,效率著實不高。所以,對于此類業務,我們在逐步遷移到spark。
3. 多用戶同時使用集群,千萬要根據業務特性使用不同的調度器。
4. 在Hadoop自身文檔還不夠完善時,有些細節千萬不能想當然,需要多試試。比如配置機器host時,hostname不能帶下劃線。
5. 千萬不要讓集群節點的磁盤容量差異太大,否則在大數據寫入并且集群使用率較大時,容易出現寫失敗等問題。
CSDN:在海量數據存儲的過程中,在讀寫上是否遇到哪些問題?有沒有調整系統默認的I/O調度策略或者是自己重寫相應的文件系統?我說的是和Ext3/Ext2一個級別的文件系統。
聶晶:默認機器一般是對硬盤做RAID5,但是RAID5相對于RAID0,寫性能也是比較差,而且比較浪費空間(Hadoop自己對數據有容災),我們使用的磁盤都是RAID0。不同的調度器對性能影響很大,通過測試使用比較適合業務的調度器,SSD和機械硬盤的差距就比較大,分別使用不同的調度策略。Ext3不同的日志級別對性能影響很大,建議關鍵業務進行性能測試,使用適合業務本身的日志級別。這里只是使用比較成熟的調度策略,自己沒有進行重寫。
CSDN:貴團隊自主研發了數據解析服務GAS,可否為大家介紹一下主要特性?據悉即將開源?
聶晶:GAS是一個通用的、實時的高性能數據解析框架,支持把不同格式的數據源,自動轉換成一種格式,為后續組件提供無差別的流式數據服務。目前,GAS支持二進制協議、ProtoBuf協議、Json協議的解析。GAS的主要特點有:
GAS目前已經在公司內部開源,目前正積極準備對外開源的有關事項。
CSDN:說到開源,可否透露一下騰訊當下使用的開源技術?都在系統中扮演著什么樣的角色?順便給大家談談使用開源技術的經驗吧。
聶晶:在兩種情況下我們會使用開源技術:第一種情況,在較簡單非關鍵的應用中有使用開源的技術,比如thrift,我們在數據查詢等一些小系統中有使用,開源技術的優點顯而易見,可以節約開發成本,很容易的可以實現簡單的需求。第二種情況,一些繞不過去的,比較成熟的,會使用開源系統,比如Hadoop,Zookeeper。我們系統中,底層和關鍵模塊都是自己開發,做到完全可控。
開源技術良莠不齊,一些冷門的或者不成熟的最好不碰。即使是成熟的開源技術,在使用中也是有各種坑。不過,成熟或者熱門的技術,好處在于可以利用各種網絡資源,也有成熟的社區,你遇到的問題,大部分別人也遇到過,容易解決。
CSDN:無縫體驗一直是服務交付中重要的一環,對于消除中間人,讓實際使用者擁有一個更好的體驗貴團隊做了哪些努力?
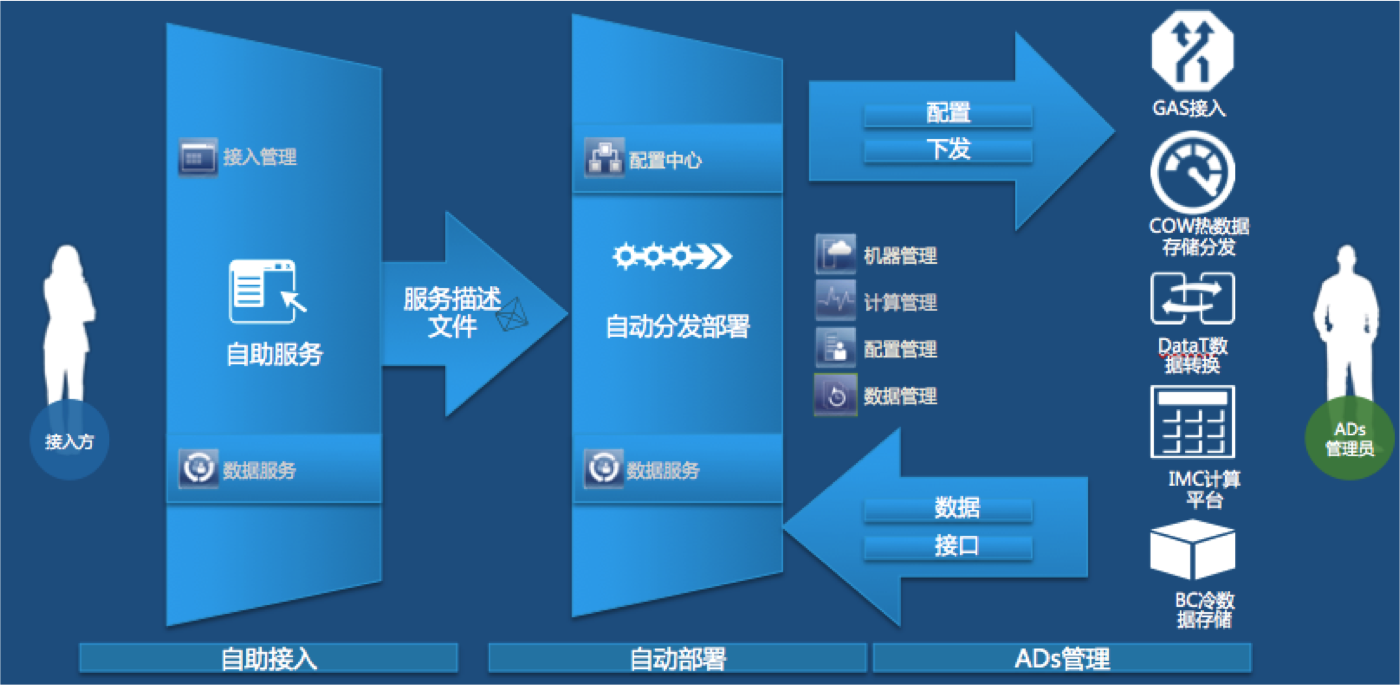
圖二 數據接入圖
聶晶:ADs可以拿出說說。原來我們接入一個數據需要產品、開發、數據管理員多次溝通、多次聯調以及多次數據質量確認,才可以完成一個數據的接入,效率極低。ADs出現之后,減少了數據管理員環節。產品通過ADs去管理、驗收數據;開發根據產品的提單開發、自助測試,確認數據質量,知會產品驗收數據。
導讀:點擊下一頁進入即將開源的騰訊通用分析工具解析博文
 免費訂閱“CSDN云計算”微信公眾號,實時掌握第一手云中消息!
免費訂閱“CSDN云計算”微信公眾號,實時掌握第一手云中消息!
CSDN作為國內最專業的云計算服務平臺,提供云計算、大數據、虛擬化、數據中心、OpenStack、CloudStack、Hadoop、Spark、機器學習、智能算法等相關云計算觀點,云計算技術,云計算平臺,云計算實踐,云計算產業資訊等服務。
面對成百上千的生產系統用戶操作數據接入落地,你是否厭倦了每次機械編寫打包解包代碼?在一次性接入多個數據時,還要對不同人聯調,費時費力,你是否還會手忙腳亂,忙中不斷出錯?是否當數據出問題了,用的時候才發現,數據已經損失大半,產品/領導壓力巨大,費一天勁才能定位問題,關鍵是下次還是不能實時發現,快速定位。
怎么辦?GAS(通用解析服務)就是為了解決上述問題,結合即通多年數據方案實踐,提出的一個數據接入的組件。一杯清茶,輕點鼠標,輕松面對大批數據接入問題。
GAS在ADs中的位置
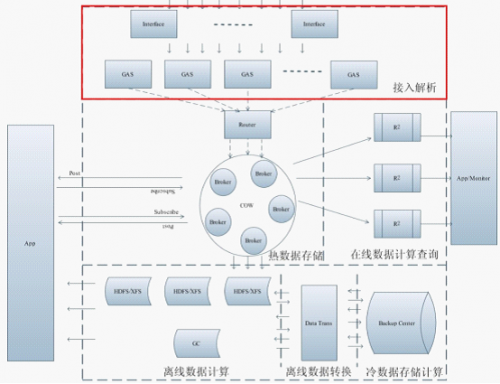
圖 1 ADs整體框架
GAS(General Analyses Service)通用數據解析服務,用協議描述語言(Protocol Description Language

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


