
【編者按】 PagerDuty是一家新興的互聯(lián)網(wǎng)創(chuàng)業(yè)公司,它是一款能夠在服務(wù)器出問題是發(fā)送提醒的產(chǎn)品,包括屏幕顯示、電話呼叫、短信通知、電郵通知等。目前AdMob、37Signals、StackOverflow、Instagram等均采用了PagerDuty作為消息通知以及突發(fā)事件處理工具。本文作者Doug Barth分享了PagerDuty是如何成功地把現(xiàn)有系統(tǒng)MySQL遷移至XtraDB集群,以及在這一過程中遇到的利與弊。
在半年前,PagerDuty公司成功地把現(xiàn)有系統(tǒng)從MySQL遷移至XtraDB集群,并在其上運行亞馬遜EC2。

舊系統(tǒng)配置分析
從配置上看,這是一個非常典型的MySQL環(huán)境:
存在的問題
兢兢業(yè)業(yè)的舊系統(tǒng)服務(wù)多年后,面對日益突出的可靠性問題,開始顯現(xiàn)出力不從心了。此外,每次進(jìn)行主服務(wù)器切換,無疑于是一場悲劇:要進(jìn)行DRBD主機(jī)切換,首先得在主服務(wù)器上中斷MySQL,脫機(jī)DRBD卷,把從服務(wù)器狀態(tài)變更為主服務(wù)器,重新載入DRBD,最后重啟MySQL。而這一整套過程會導(dǎo)致服務(wù)中斷,因為MySQL在由中斷到重啟的過程中,我們設(shè)置了一個冷卻緩沖池,在系統(tǒng)服務(wù)重回正軌前這個冷卻機(jī)制需要時間預(yù)熱。
我們嘗試通過Percona的緩沖池恢復(fù)(buffer-pool-restore)功能來減少中斷時間,但這相對于我們體型龐大的緩沖池來說如同蚍蜉撼樹。同時該功能會增加額外的系統(tǒng)資源開銷。還有個問題是,一旦發(fā)生意外的主服務(wù)器切換,異步從服務(wù)器將停止運作,必須手動重啟。
擁抱XtraDB集群的原因
XtraDB集群的特色:相校于之前的雙機(jī)系統(tǒng),集群中采用的是三機(jī)同時運作,兩兩進(jìn)行同步備份。因此連接切換時間大為減少。
支持多主服務(wù)器同時在線,每個主服務(wù)器擁有一個熱緩沖池。異步從服務(wù)器可以選擇任何節(jié)點作為主機(jī),節(jié)點間的轉(zhuǎn)移不會中斷備份復(fù)制進(jìn)程。
自動化的節(jié)點機(jī)制與我們目前的自動化系統(tǒng)配合良好。配置新節(jié)點后,我們只需提交一個節(jié)點地址,新節(jié)點將會自動收到一個數(shù)據(jù)備份集,同步數(shù)據(jù)后會加載到主服務(wù)器群中。
前期準(zhǔn)備
將XtraDB集群接入現(xiàn)行系統(tǒng),需要進(jìn)行一定的前期準(zhǔn)備。部分是簡單的MySQL微調(diào),其余的是一些基礎(chǔ)化的操作。
在MySQL上的操作:
除上述MySQL端的操作,為了能在DRBD服務(wù)器上進(jìn)行獨立的測試,應(yīng)用系統(tǒng)端需要進(jìn)行如下的變更:
模式變更的選擇
在XtraDB集群中進(jìn)行模式變動是牽一發(fā)而動全身的。在集群有兩種實現(xiàn)方式,一種是total order isolation (TOI,總序分離式),另外一種是rolling schema upgrade (RSU,滾動模式升級)。
在RSU模式下,允許單獨地對節(jié)點進(jìn)行更新。當(dāng)執(zhí)行DDL語句時,按序同步各個節(jié)點,執(zhí)行完畢后再重新加入集群。但是這個功能會招致不穩(wěn)定性,同時數(shù)據(jù)的大量刷新動作引起的系統(tǒng)問題是不可避免的,由于RSU需要等待DDL語句執(zhí)行完畢才能進(jìn)行緩存刷新。
相比之下,TOI的更新操作是一次性同步所有節(jié)點,阻斷集群通信直到更新完成。我們衡量一番后,決定采用TOI模式。由于系統(tǒng)中斷時間較短,所以這次沒有對集群進(jìn)行阻斷。
遷移過程
首先,我們在現(xiàn)系統(tǒng)中建立一個集群作為現(xiàn)DRBD數(shù)據(jù)庫的一個從屬。當(dāng)該從屬數(shù)據(jù)庫接收到所有寫入操作時,我們可以進(jìn)行壓力測試,看看它的承載能力如何;同時會進(jìn)行相關(guān)數(shù)據(jù)收集和分析。
在進(jìn)行一系列相關(guān)基準(zhǔn)測試后,我們發(fā)現(xiàn)了兩點技術(shù)細(xì)節(jié)是能夠幫助實現(xiàn)遷移前后的系統(tǒng)性能趨于一致:
進(jìn)行一番測試后,XtraDB集群的各項指標(biāo)令人滿意,我們接下來開始著手進(jìn)行實際切換。
首先把所有測試環(huán)境下的配置進(jìn)行備份。因為一旦cluster出現(xiàn)宕機(jī),我們可以快速恢復(fù)其至一個單一節(jié)點cluster。我們編寫了具體的操作程序以及進(jìn)行了相關(guān)壓力測試。
在對現(xiàn)有系統(tǒng)的兩個DRBD服務(wù)器進(jìn)行從屬服務(wù)器設(shè)置后,我們還設(shè)置了其余服務(wù)器的從屬設(shè)置(例如:災(zāi)難恢復(fù),備份等)。一切就緒后,我們執(zhí)行了一次常規(guī)的從屬升級操作把系統(tǒng)切換到新環(huán)境中。
切換前后的架構(gòu)變化如下圖所示:
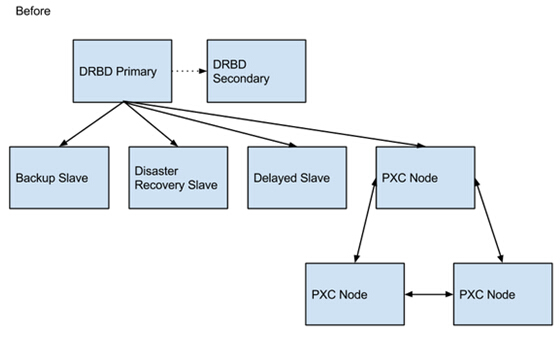
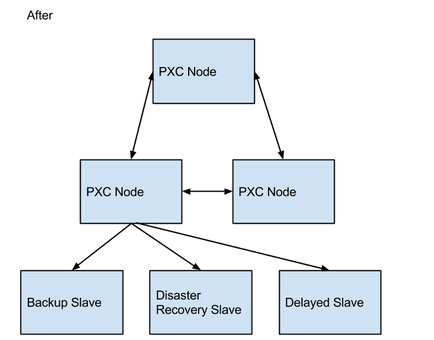
切換后的優(yōu)點分析
對正在運行的cluster進(jìn)行重啟和更新時,成功避免了之前造成的通信中斷影響。成功以TOI模式(pt-online-schema-change)進(jìn)行模式變更。寫入沖突處理能力得到優(yōu)化提升。當(dāng)發(fā)現(xiàn)一個沖突后,XtraDB Cluster會返回一個死鎖錯誤信息,在以TOI模式執(zhí)行DDL語句時同樣可觸發(fā)該錯誤信息返回。之后,沖突錯誤會導(dǎo)致應(yīng)用程序服務(wù)器返回一個503錯誤,而我們的負(fù)載平衡層設(shè)置會捕獲該錯誤,隨后會嘗試在另外的服務(wù)器上重新遞交寫入請求。切換后的缺點分析
部分cluster的關(guān)鍵狀態(tài)計數(shù)器是按狀態(tài)改變的,例如在執(zhí)行顯示全局狀態(tài)指令后(SHOW GLOBAL STATUS),其值會重設(shè)為0。這樣會造成很難根據(jù)計數(shù)器來進(jìn)行重要的狀態(tài)監(jiān)控,例如流控制,因為其值的頻繁變更會造成無法準(zhǔn)確監(jiān)控系統(tǒng)的狀態(tài)(在使用XtraDB Cluster 5.6的Galera 3.x系統(tǒng)中,該問題已得到解決)。當(dāng)一寫入操作沖突發(fā)生時,MySQL動態(tài)記錄適配器會忽略來自交互語句拋出的異常。英文出自: Highscalability

程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學(xué)習(xí),php手冊,CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學(xué)習(xí),原版權(quán)很多不明,如有侵權(quán)請聯(lián)系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權(quán)所有


