
【編者按】Spark,發源于美國加州大學伯克利分校AMPLab的集群計算平臺,當下已成為Apache基金會的頂級項目。而在不久前,知名Hadoop解決方案供應商Cloudera已宣布了其發行版對Spark的支持。毫無疑問,Spark已成為流行的大數據計算框架之一,而據Gigaom Derrick Harris的一則消息,MapR近日也宣布了對Spark的支持,同時這個Hadoop先鋒的支持將更加徹底。
2014年4月19日“ 中國Spark技術峰會”(Spark Summit China 2014)將在北京召開,國內外Apache Spark社區成員和企業用戶將首次齊聚北京。AMPLab、Databricks、Intel、淘寶、網易等公司的Spark貢獻者及一線開發者將分享 他們在生產環境中的Spark項目經驗和最佳實踐方案。
下為譯文:
MapR是知名的Hadoop供應商,最近該公司為其Hadoop發行版中添加了完整的Spark堆棧。這是一項明智之舉,更說明Spark很可能成為未來的數據處理框架。
MapR也是應用Apache Spark的先驅者,周二,MapR宣布將整合Spark棧至其Hadoop版本,并將此作為與Spark初創公司Databricks(Opm Stoica,創始人及CEO,見上圖)合作的一部分。Spark使處理大數據工作負載變得更為便捷,也使得大數據工作負載編程變得更容易。
Spark最初是加州伯克利大學開發的一款內存處理框架,隨后它逐漸流行起來,但它真正的崛起還是在2013年9月――被Databricks正式推出。隨后,Cloudera將Spark整合到其Hadoop發行版(作為與Databricks合作的一部分)。同時,許多按Hadoop設計的項目和公司都計劃將支持Spark或直接轉向Spark。
這其中包括Cloudera的Oryx項目,分析初創公司Platfora,甚至包括Apache Mahout項目;也包括參與Databricks認證程序的公司們。
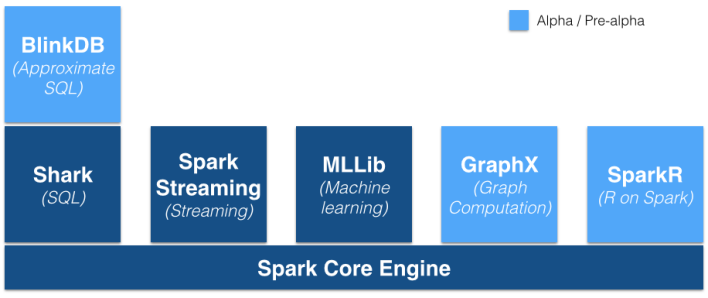
Spark現在如此盛行,這是因為它既做到了MapReduce可以做到的,還做到了MapReduce沒能做到的。MapReduce是傳統的Hadoop數據處理框架,它速度慢(它采用的是批處理),編程繁瑣。Spark快捷、靈活――這使得Spark可以更好的處理諸如機器學習、圖形處理和、交互式查詢類的任務――而且易于編程。Spark是用Scala寫的,不過它也支持Java,Python與R語言。
YARN是資源管理系統,也是Hadoop 2.0的一部分,YARN允許多處理框架同時運行于同一集群,這些框架都有訪問Hadoop分布式文件系統進行存儲的權限。這使得Hadoop對Spark的支持成為可能。
MapR的這條新聞最有趣的地方是,MapR提供了對Spark棧的全部支持――這包括Shark SQL查詢引擎(它本質上說一個更快Apache Hive)和MLLib機器學習庫――然而Cloudera卻不支持Shark。這大概是因為Cloudera還在力推它的Impala SQL查詢引擎,而MapReduce也沒有包括這個引擎。MapR一直引領交互SQL查詢項目Apache Drill的發展;此外隨著Drill的到來,MapR也添加了對HP Vertica的本地支持。
從MapR的角度,通過整合Spark這一用戶需求的功能提高了其在業界的地位(先前MapR受到的關注度是遠少于競爭對手Cloudera和Hortonworks的)。例如,MapR現在開發了自己的HBase NoSQL數據存儲,相較于其他Hadoop發行版包含的開源版本,這個數據存儲功能更齊全。
正是諸如Spark類的技術――以及任何可以運行在YARN上的技術――使得Hadoop成為有潛力顛覆現有數據行業供應商的新生力量。Apache Hadoop一直提供廉價、開源的存儲,不過現在生態系統已經將Hadoop變為一個可以在數據之上做很多事情的平臺。在未來的幾年,我們將看到更多的分析應用、甚至是數據庫采用Spark或類似的技術作為引擎。
原文鏈接: Spark is now part of MapR’s Hadoop distro, too(翻譯/蔡仁君 責編/仲浩)
以“ 云計算大數據 推動智慧中國 ”為主題的 第六屆中國云計算大會 將于5月20-23日在北京國家會議中心隆重舉辦。產業觀察、技術培訓、主題論壇、行業研討,內容豐富,干貨十足。票價優惠,馬上 報名 !

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


