
編者按:在hadoop中,Namenode負責對HDFS的metadata的持久化存儲,并且處理來自客戶端的對HDFS的各種操作的交互反饋。張曉豐的博客給我們詳細講述了hadoop-0.20.2-cdh3u1版本下,通過regular方式啟動時的代碼流程分析。以下為原文:
在Namenode啟動時會首先去構造Configuration對象,這個對象會貫穿代碼的整個執行過程,不過在構造的時候它并沒有去加載解析core-site.xml、hdfs-site.xml等配置文件,而是在第一次要使用到這些配置的時候才去解析,解析后保存在Configuration類里的一個Properties的對象里,在這之后才真正的去用Namenode的構造方法構造Namenode對象。
這里簡單講一下Namenode類。在Namenode里有一個FSNamesystem類的對象,這個類才真正保存了文件系統的信息。它的內部主要是通過保存幾個重要的映射來達到這個目的的,比如文件與block的映射,機器(也就是各個datanode節點)與block的映射,block與機器的映射等。除了FSNamesystem類的對象,Namenode 里還有兩個Server類型的成員,Server類主要是用于RPC請求的服務端實現。為什么會有兩個RPC請求的服務端實現呢?其實這只是cdh3u1版本在apache的0.20.2版本上做的二次開發。在apache的0.20.2版本里只有一個RPC請求的服務端,它處理了hadoop集群內部節點和客戶端發起的所有RPC請求;然而在cdh3u1里把這兩種來源的RPC請求分開來處理了,一個Server處理hadoop集群內部節點的請求,另一個Server處理來自客戶端發起的RPC請求;當然,要在配置文件里配置是否使用單獨一個Server來處理內部的RPC請求,否則還是會只啟動一個Server來處理。個人覺得分開來處理是有好處的,這樣的話內部和客戶端的RPC請求不會相互影響了,也會提高客戶端得到響應的速度。
在Namenode的構造方法里會去調用initialize方法,在這個方法里才做了實質性的工作,包括啟動RPC服務,啟動web服務和構造FSNamesystem對象。RPC留在最后講,這里先進一下FSNamesystem類。
FSNamesystem類里有幾個重要的數據結構,它們對應的屬性是BlocksMap、CurruptReplicasMap、DatanodeMap、RecentInvalidateSets、ExcessReplicateMap、Heartbeats。BlocksMap是BlocksMap類的對象,它保存了block和blockInfo的映射(在apache的0.20.2版本里保存的是blockInfo到blockInfo的映射,),BlocksMap類(cdh3u1版)的實現與JDK里HashMap的實現類似,里面也有一個內部類用于存放實際的element,在構造BlocksMap對象的時候會計算出系統所能所能管理的block的數量,該數量是用JVM的位數和能使用的最大內存計算出來的。CurruptReplicasMap也是一個map,它保存了所有損壞的block,只有block的所有副本都損壞了,該block才被認為是損壞的,如果后來又收到了該block的副本report,那么會從CurruptReplicasMap里remove掉該block。DatanodeMap里保存了所有的曾經連接過該Namenode的datanode的描述,用DatanodeDescriptor類表示。
RecentInvalidateSets保存了最近失效的block,這些block被認為放在出現了某些問題的機器上。ExcessReplicateMap保存了機器與該機器上多余的block的映射,這些block最終會被刪除掉。Heartbeats里保存了當前發送心跳包的datanode節點,它是DatanodeMap的一個子集。
除了以上講的數據結構外,FSNamesystem里還有一個重要的屬性dir,它是FSDirectory的對象,這個類維護了分布式文件系統的層次結構,它內部有一個屬性rootDir,INodeDirectoryWithQuota類型的,代表了文件系統的根目錄。這里先講一下層次結構的組成。Hadoop里有一個INode類,該類是構造文件系統層次結構最基礎的一個類,它包含了目錄和文件共有的一些屬性,比如訪問時間,最近修改時間,權限等。從INode類派生下來的有INodeDirectory和INodeFile兩個類,分別代表了目錄和文件。INodeDirectory里有一個List類型的成員children,正是有了這個成員才構筑起了文件系統的層次結構;由于文件內部不可能還有文件或目錄,所以INodeFile里沒有類似的成員;但是Hadoop里文件是分成許多block的,所以INodeFile里維護了一個BlockInfo的數組。另外INodeDirectoryWithQuota繼承了INodeDirectory,INodeFileUnderConstruction繼承了INodeFile;前者表示一個帶有配額的目錄,后者表示正在被客戶端修改的文件,它內部保存了文件與客戶端的租約。綜上所述,INode,INodeDirectory,INodeFile,INodeDirectoryWithQuota,INodeFileUnderConstruction五個類共同構筑起了HDFS的文件層次結構。
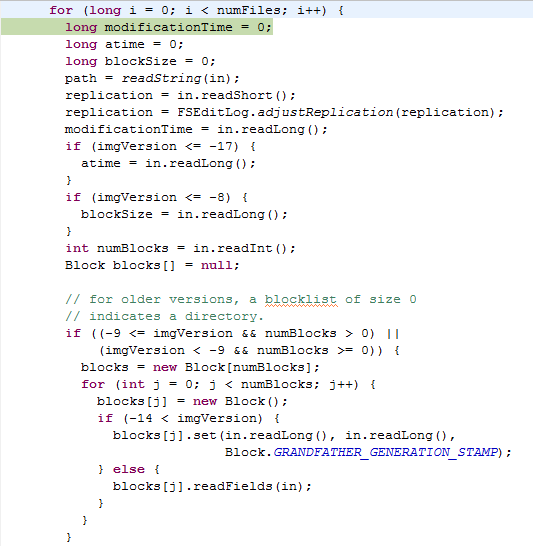
講了hadoop是怎樣構建起分布式文件系統的層次結構后,揭下來我們再來看看FSDirectory對象的創建。FSDirectory類里有一個FSImage類型的成員,而FSImage類里又有一個FSEditLog類型的成員;FSImage類代表了存放文件系統元數據的fsimage文件,FSEditLog代表了對文件系統的修改,對應的文件是edits。每次Namenode啟動的時候會讀取fsimage文件來構造文件系統的層次結構,而且還會將edits和fsimage合并為一個新的fsimage文件。這里要注意一下,hadoop的本地存放元數據以及檢查點的目錄由一個特別的類Storage來表示,FSImage類就繼承了Storage類。我剛開始讀源碼的時候,總是以為Storage就表示了分布式文件系統的目錄,其實不然,它表示的是本地的存放目錄。Storage類繼承了StorageInfo類,StorageInfo類里是一些目錄的共有信息,包括創建時間,namespaceID等;在Storage類里,有一個枚舉類型StorageState表示Storage的狀態,還有一個接口StorageDirType表示Storage的類型,在FSImage類里實現了這個接口,從中可以看出Namenode Storage有三種類型,分別是EDITS,IMAGE,IMAGE_AND_EDITS。其實FSDirectory的創建的主要工作就是初始化fsimage對象,真正的讀取fsimage文件的操作在FSDirectory類的loadFSImage(File)方法里,該方法讀取fsimage文件來構造FSDirectory類里的rootDir成員,它代表了分布式文件系統的根目錄。下面是讀取fsimage文件的代碼:
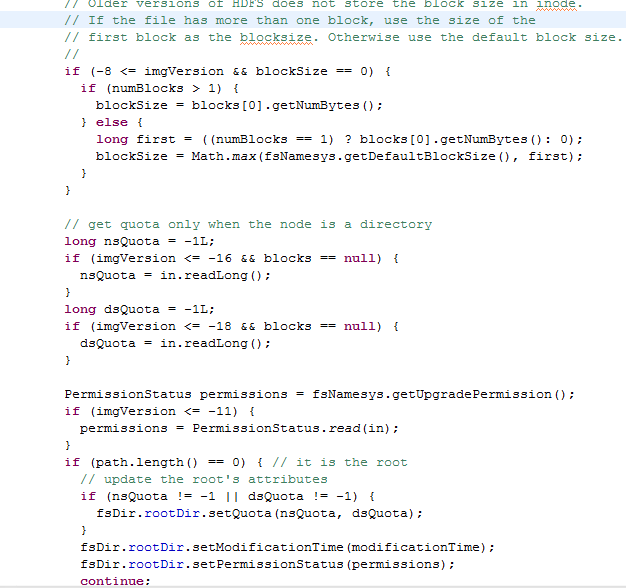

在FSNamesystem對象創建完后會啟動幾個后臺守護線程,分別是PendingReplicaitonBlocks$PendingReplicationMonitor、FSNamesystem$HeartbeatMonitor,FSNamesystem$ReplicationMonitor、LeaseManager$Monitor、DecommissionManager$Monitor。HeartbeatMonitor會定期檢查已注冊的數據節點發來的心跳包,每次檢測的時間間隔為heartbeatRecheckInterval ,可以通過heartbeat.recheck.interval來配置;該線程會根據上次發送心跳包的時間與現在的時間差來判斷是否超出heartbeatExpireInterval,若超出則認為該數據節點已dead。FSNamesystem$ReplicationMonitor線程會監視整個集群的副本數量是否滿足設定的值,如果某個block的副本不足,它會選擇一些datanode去copy副本,副本復制是有優先級的,副本數量越少的block具有更高的優先級,系統會首先去copy這些block。當然副本的copy是需要時間的,系統是怎么知道副本copy成功的呢?這就是PendingReplicationMonitor線程的作用了,它內部有一個成員保存了正在copy的block的信息,它會定期去檢查這些在某個數據節點上copy的副本是否copy成功,如果超出了設定的時間間隔,如果超出了,那么對應的block會被放入timedOutItems里,對于這些超時的block,replicationMonitor會再交給其他數據節點復制。DecommissionManager$Monitor會監視正在退役的數據節點的狀態,當某個數據節點被標示為退役狀態時,系統并不能馬上讓該數據節點退役,而是要等該數據節點上的block被復制完成后,才能允許它退役,DecommissionManager$Monitor就是用來檢測這些數據節點上的block是否滿足了副本因子,只有滿足了副本因子,才能允許該節點真正地退役。最后講一下LeaseManager$Monitor。首先我們要知道hdfs上的文件是不允許被多個客戶端同時操作的,那hadoop是怎樣避免沖突的呢?當然是通過leaseManager了。當客戶端向Namenode發起請求要操作某個文件的時候,首先會得到了一個文件租約lease,一個文件租約和一個文件,一個客戶端相關聯;若此時其他客戶端要想操作這個文件,那么它得不到這個租約,也就不能操作該文件,這樣就避免了多客戶端同時操作某個文件。客戶端會定期去更新租約的開始時間使得該客戶端可以持續操作這個文件。當客戶端釋放這個文件的時候,客戶端也會發請求告訴服務端刪除掉該租約。在客戶端突然宕機來不及告訴Namenode釋放租約的情況下,這些租約會過期。LeaseManager$Monitor會檢查那些過期的租約并釋放掉,好讓其他客戶端能操作該文件。
最后再來談談hadoop的RPC框架。首先我們要搞清楚RPC框架類的繼承結構。有關RPC框架所涉及的類都在ipc包下。ipc包下有三個主要的類,分別是Server,Client和RPC;RPC類里還有一個Server內部類,該內部類繼承了ipc下的Server類。這里我講的只涉及到RPC框架的服務端實現,也就是Server類和RPC類,不會涉及到Client類。在Server類里,存在Call,Listener,Responer,Connection,Handler這幾個內部類;在Listener類里還有一個Reader內部類。下圖是我從網上找的RPC機制圖:
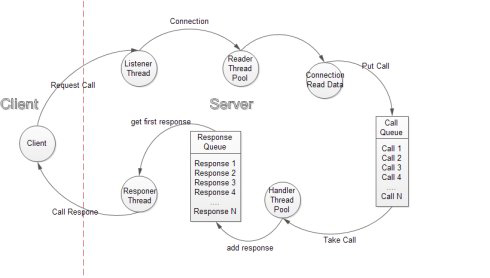
當一個請求到達時,listener會選取一個reader并調用該reader得registerChannel方法將得到的socketChannel注冊到reader的selector中。然后構造一個Connection,將該connection放入Server類里的connectionList成員里。源代碼如下:
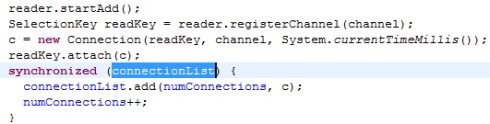
接下來就到了reader線層的執行了,在reader的run方法里會調用listener的doRead(SelectionKey)方法,然后從selectionKey里得到Connection對象,最后再去調用connection對象的readAndProcess()方法,之后還調用了connection對象的幾個方法,最后再connection的processData方法里創建一個call對象,加入到server類的call隊列里。接下來就到了Handler線層的執行了。在handler的run方法里會從call隊列中取出一個call對象,然后用這個call的信息去調用Server類的call方法得到一個value(其實是調用了server類保存的Namenode實例的方法,通常情況下,會調用到FSNamesystem類的方法上去)。最后調用setupResponse方法將value以及這次調用所產生的其他信息,如錯誤信息等賦值給call對象的response屬性,再調用Responser的doResponse方法將這個call加入到responseQuene中。最后就剩下一個Responser了,該線程的工作很簡單,也就是從responseQuene中取出call,將這次調用的結果發回給客戶端,再關閉連接而已。
原文鏈接:Namenode啟動過程分析(責編:Arron)

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


