
【編者按】人工智能被認為是下一個互聯網大事件,當下,谷歌、微軟、百度等知名的高科技公司爭相投入資源,占領深度學習的技術制高點,百度在2014年5月19日宣布曾領導谷歌的深度學習項目――Google Brain ,被譽為谷歌大腦之父的Andrew Ng加盟百度,正式領導百度研究院工作,尤其是Baidu Brain計劃。7月7日,他應邀做客中國科學院自動化研究所,發表了《Deep Learning:Overview and trends》的學術報告,本文來自新浪梁斌的博客。
以下為原文:
一早出發,8點20就趕到現場, 人越聚越多,Ng提前幾分鐘到達現場,掌聲一片。
Ng的報告總體上提到了五個方向。
1. Deep Learning相比于傳統方法的優勢
首先,一個很直觀的圖,隨著訓練量的提高,傳統方法很快走到天花板,而Deep Learning的效果還能持續走高,后來這個在提問環節也有同學問道,是否會一直提高,Andrew Ng也坦誠需要面對不同的問題來討論,而且任何方法都有天花板。

這個問題蠻關鍵的,我補充回答一下,其實這是一個特征表達力的問題,傳統方法特征表達力,不如Deep Learning的多層學習得到的更有效果的表達。舉個例子,假定有一種疾病,這種疾病容易在個高且胖的人群,以及個矮且瘦的人群中易感。那么任意從給一個特征角度上看,比如肥胖,那么胖的這部分人中,得此病的概率為50%,不胖的也是50%,那么"胖"這個特征沒有表達力。
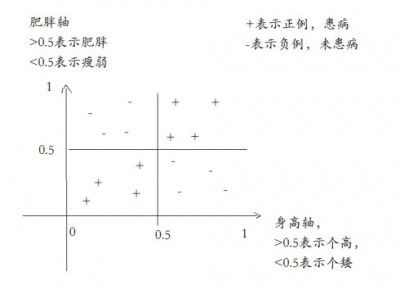
用學術上的術語來說,身高和體型是兩個Marginally independent的變量,即如果觀察到了他們產生的結果,他們就不獨立了。也就是如果身高和體型在用于檢測這種疾病的時候,他們就不獨立了,因此需要有一種特征表示的方式來表示他們的這種不獨立性,能夠combine他們以形成更好的特征。而這種更結構化的特征,需要大量的語料才能training到位。而獨立性的特征,往往少部分語料就可以獲得很好的結果,但隨著語料數量的提高,無法observe到結構化的特征,因此更多的語料就浪費了。我們都知道這是AI領域的XOR問題,也就是二層神經網絡就能求解,換言之,多層神經網絡mining出來更好的特征。
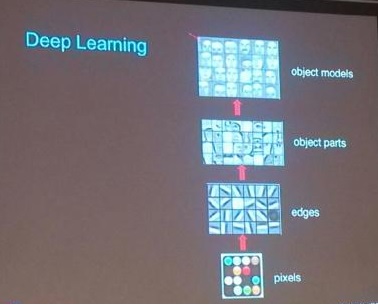
接著Ng也直觀的展示了,從像素級特征(表達力最弱)到edges級特征,直到object級特征。 從edges特征大家看到的這個形式,其實是深度神經網絡的edges中的一個小塊,就是input layer到第一個hidden layer之間的一組邊(如果是RBM 的話)或者是第一個hidden layer到output layer的一組邊,這組邊可以理解成training的成果。而hidden layer是一個sparse coding的向量,用來combine不同組的邊來還原出input layer。
因此可以看到,通過深度學習的處理,無需tagged data,通過自學習的方式,就可以做到特征的表達力從像素級,提高到了 object models,多么美妙啊,難怪Ng用了Amazing這個詞,而且再一次地露出了特有的微笑。
2. Deep Learning存在的問題
Ng提到了,通常學生試驗在10 million connections這個水平,因為再大已經超出計算的能力,但如果采用并發的方法,160000萬個CPUs的情況下,可以達到1 billion connections這個水平。如果采用特制的GPU來計算,可以達到10 billion connections的水平。
從我自己的實驗結果看,目前做千萬connection是沒問題的,時機成熟我就開放出來,但受限于CPU在向量計算的劣勢,再大的話,每一輪訓練的時間就會大大提高,變得不可計算,而分布式Parameter server的搞法,雖然能夠第一步把語料shard一下,然后各自訓練,到了最高層用類似transform learning的法子再combine(這段話是我自己猜測的,Ng的報告這里我沒聽太懂,圖片是按照記憶畫出)。
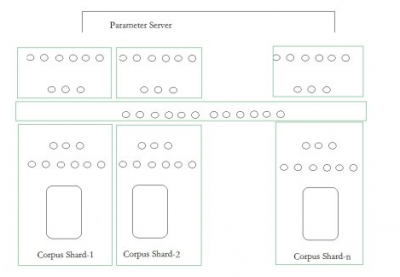
我個人的理解,就是一個巨大語料切成n個部分,每個部分產生表達力強的特征,而這些表達力強的特征在一個階段,就是那個長條哪里進行combine,也就是這個hidden
layer可以很好的表達來自不同shard的特征,最后在展開各層,用不同shard上的tagged data 來進一步調整每條邊的權重。
3. Deep Learning的Idea

這個可能沒什么可說的,但我認為很重要,這段話不難翻譯,人腦中大部分感知器是一個非常簡單的計算過程。但通過組合可以達到很高的理解力。但問題是如何組合,感知的過程如何從低級階段到高級階段,從明暗,色彩的感知,到人類喜怒哀樂的情感,整個過程的每一步可能都是naive得,但整個認知鏈條的末端一定是語義的,有感情的,上升到概念的。另外,通常還有一個體會,比如看一本小說,腦海中就能自然浮現畫面,可見不同神經感知器也不是完全獨立的,而是彼此聯系的。
4. Deep Learning的一些成果
報告中提到很多成果,特別是提到了圖像識別中,在DL面前,SIFT特征提取算法弱爆了,我還是為Ng的自信和霸氣,略震了一下。按照常規,學術界的同志應該謙虛,尊重下老前輩,尊重下傳統的。
后來的提問環節,也有同學問到,那些old 算法框架怎么辦呢?Ng說無論怎樣,這就是科學技術的趨勢,當一個東西產生明顯效果后,越來越多的方法會采用這些新方法,而傳統方法,不是說研究者就立馬到zero,但的確會fewer and fewer。當時我心里想,無論如何如何,總得有留下少部分堅守的同志,沒準10年后翻身也難說,但大部隊應該撲新方法的。

5. 未來趨勢

Andrew教授對深度學習未來的發展進行了展望:1)將會越來越重視對無標記數據的特征學習;2)深度學習將全面占領計算機視覺和語音識別領域;3)向量化表示的提出將對NLP領域產生重大影響,并將對機器翻譯、網頁搜索和對話系統等性能提升有所幫助。總的來說,模型的規模依舊是最大的挑戰。
提問環節有很多有趣的話題,比如有人問百度,以及Andrew Ng本人對Spark的評價,Ng回答到,百度用了很多開源工具,但機器學習的很多問題太Uniq了,太特殊了,而Spark這種通用的東西很難滿足需求,當然不是說Spark不好,只是Ng本人也很少用(用了Less這個詞匯)。
還有包括為什么加入百度,Ng說了三個原因,第一他認為機器學習是Transform世界,Transform互聯網的一種方式,相比coursera更加感興趣。第二百度擁有大量優秀的科學家,高質量的同事,比如余凱,張潼,徐偉同志等等。第三,百度擁有大量的data, 還有個同學要DL的Reading List,Ng給了個這個:http://deeplearning.stanford.edu/wiki/index.php/UFLDL_Recommended_Readings 。另外根據網友@ fiona_duan 的反饋。最后Andrew提到的是他出生于香港,長在英國和新加坡,之后在美求學和生活。他和妻子都在美國。他妻子叫Carol Reiley. Carol 是約翰?霍普金斯大學的醫學博士以及在讀計算機博士,研究方向是生物醫學方向的機器人應用。
人物介紹:Andrew NG教授2014年5月16日加入百度,擔任百度公司首席科學家,負責百度研究院的領導工作。加入百度前任斯坦福大學計算機科學系和電氣工程系的副教授,斯坦福人工智能實驗室的主任。Andrew
Ng是深度學習領域的頂級專家,曾領導谷歌的深度學習項目――Google Brain ,被譽為谷歌大腦之父。Andrew Ng還是在線教育平臺Coursera聯合創始人。2013年《時代》雜志評選的全球最具影響力百大人物中上榜的十六名科技人物之一。
 免費訂閱“CSDN云計算”微信公眾號,實時掌握第一手云中消息!
免費訂閱“CSDN云計算”微信公眾號,實時掌握第一手云中消息!
CSDN作為國內最專業的云計算服務平臺,提供云計算、大數據、虛擬化、數據中心、OpenStack、CloudStack、Hadoop、Spark、機器學習、智能算法等相關云計算觀點,云計算技術,云計算平臺,云計算實踐,云計算產業資訊等服務。

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


