
【編者按】Netflix公司擁有海量的視頻、圖片數據,公司不斷創新技術提升用戶使用體驗,最新消息顯示Netflix承認正在開發新的技術開展人工智能領域的應用,該公司廣泛采用高級人工智能技術,尤其以深度學習技術被大家所熟知。著眼深度學習可以讓Netflix的電影推薦更準確,但是深度學習領域還有很多技術難題未被解決,Netflix技術博客網站的Alex chen等人結合自身實踐,分享了在AWS上實現分布式人工智能網絡的經驗。
以下為譯文:
在以前的博客中提到,Netflix一直不斷創新,努力通過尋找更好的方法為我們的會員找到最好的電影和電視節目。當一個新的算法技術例如深度學習在其他領域(如圖像識別、神經成像、語言模型和語音識別)展現非常好的前景時,我們沒有驚喜,而是試圖找出如何應用這些技術來改善我們的產品。在這篇文章中,我們將和大家分享在Netflix實驗這些方法過程中建立基礎設施的一些經驗。希望對從事類似算法的人有所幫助,尤其是那些也使用AWS基礎設施的人們。然而,我們不會詳細說明我們如何使用人工神經元網絡的變量實現個性化,因為它現在還在研究階段。
許多研究人員指出,大部分流行的深度學習算法技術已經為大家熟知和了解。最近這一領域的革新已經能讓這些技術能夠實際應用,包括設計和實現的架構,可以在合理的資源和時間的情況下執行這些技術。第一個大規模深度學習成功實例是連續幾天使用1000臺機器的16000個CPU內核訓練一個神經網絡。盡管這具有里程碑意義,但是所需的基礎設施、成本、計算時間仍然是不實際的。
Andrew Ng和他的團隊解決了這個問題。他們使用強大而廉價的GPU代替大型集群的CPU,使用此體系結構僅用3臺機器在幾天內就訓練出比原來大6.5倍的模型。在另一項研究中,Schwenk等人表明,在GPU上訓練這些模型可以大大提高性能,即使和高端的多核CPU相比。
考慮到我們在云計算領域的技術和領導能力,我們利用GPU和AWS的優勢,實現大規模神經網絡訓練系統。我們想要使用合理數量的機器,利用神經網絡方法實現強大的機器學習解決方案。我們還需要避免在一個專用的數據中心里使用特殊的機器,按需計算的能力可以在AWS上獲得。
分布式機器學習的層次
你們中的一些人可能會認為上面描述的場景不是傳統意義上的分布式機器學習。例如,在上面所提到Ng等人,他們將學習算法本身分配在不同的機器上。雖然這種方法在某些情況下可能有意義,但是我們發現它們并不是很規范,特別是當一個數據集可以存儲在單一實例上。要理解為什么,我們首先需要解釋可分布式模型的不同層次。
在標準情況下,我們會有一個特定的模型與多個實例。這些實例在你的問題空間可能對應于不同的分區。典型的情況是不同國家或地區要有不同的模型訓練,因為分布特征甚至主題空間各個國家和地區都是不同的。這代表第一個初始級別,在這里我們可以決定分配學習過程。我們可以,例如,Netflix在41個國家運營,我們可以在每個國家都進行獨立的機器訓練,因為每個地區的訓練可以完全獨立。
然而,正如上面所解釋的,培訓單一實例實際上意味著訓練和測試數個模型,每個對應一個不同的hyperparameters組合。這是第二個層次,過程可以被分配。這個級別是特別有趣的,如果有許多參數優化和一個好的策略優化它們,如貝葉斯優化與高斯過程。運行之間唯一的的通信是hyperparameter設置和測試評價指標。
最后,該算法訓練本身可以是分布式的。這也是有趣的,但它是有代價的。例如,培訓ANN是一個比較集中通信的過程。考慮到你可能會有成千上萬的核心在一個GPU實例上,如果你能充分利用GPU,避免進入昂貴的跨機器通信場景,這將是很方便的。因為在一臺機器上使用內存通信通常遠遠快于通過網絡。
下面下面的偽代碼演示了這三個層次:

在本文里,我們將闡述在我們的用例中如何解決級別1和2分布。請注意,我們不需要解決3層分布的原因之一是因為我們的模型有數百萬的參數。
優化CUDA Kernel
我們處理分布問題之前,必須確保基于GPU的并行訓練是有效的。我們首先在自己開發的機器上進行概念驗證,然后再來處理如何擴展機器問題。我們開始使用Nvidia Quadro 600 GPU的聯想S20工作站。這個GPU 有98內核,并且為我們的實驗提供了一個有用的基準,特別是考慮到我們打算在AWS上使用一個更強大的機器。我們第一次嘗試訓練神經網絡模型花了7個小時。然后我們在EC2的cg1.4xlarge實例中運行相同的代碼來訓練該模型,它有一個更強大的448內核的Tesla M2050
。然而,訓練時間從7小時上升到20小時以上。分析表明,大部分時間是花在Nvidia性能原始庫函數調用,例如nppsMulC_32f_I、nppsExp_32f_I。cg1實例比聯想S20重復調用npps函數多花費了十幾倍的系統時間。
當我們試圖找出問題的根源,我們使用定制的cuda
kernel重新實現npps函數,例如將nppsMulC_32f_I函數替換為:

用這種方法取代所有npps函數這樣的神經網絡代碼使cg1實例上的總培訓時間從20多小時減少到47分鐘。訓練100萬樣本用去96秒GPU的時間。使用相同的方法在聯想S20總訓練時間也從7小時減少到2小時。
PCI 配置空間和虛擬環境
當我們處理這個問題時,我們也曾與AWS團隊找到一個好的解決方案,不需要內核補丁。在這樣做的時候,我們發現,相關性能下降與NVreg_CheckPCIConfigSpace內核參數有關。從RedHat得知,將這個參數設置為0,將會讓訪問PCI配置空間非常緩慢。在虛擬環境中,如AWS,這些訪問導致hypervisor陷阱,導致更慢的訪問。
NVreg_CheckPCIConfigSpace是一個參數,可以設置:
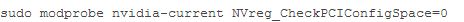
我們使用基準測試這個參數變化的影響,反復調用MulC(128 x1000次)。下面是我們cg1.4xlarge實例運行時間(秒):

我們還應該指出,還有其他方法,我們到目前為止還沒有找到,但對其它也是有用的。首先,我們可以將我們的代碼優化,通過應用一個內核融合技巧,合并一些計算步驟到一個內核將會減少內存訪問。最后,我們可以考慮使用Theano,GPU匹配Python編譯器,也應該可以在這些情況下提高性能。
G2 實例
雖然我們最初的工作是使用cg1.4xlarge EC2實例,但是我們對新的EC2 GPU g2.2xlarge實例類型同樣感興趣,它具有1536內核 GRID K520 GPU (GK104 chip)。目前我們的應用程序也被GPU內存帶寬限制,GRID K520內存帶寬是198 GB /秒,相比Tesla M2050的148 GB /秒已經有所改善。當然,使用GPU與更快的內存將會更快(例如TITAN的內存帶寬達到288 GB / sec)。
我們用默認的函數和自己的函數在g2.2xlarge實例上重復相同的比較(有或沒有PCI空間訪問)。
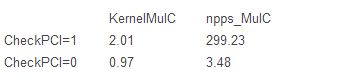
最初令人驚訝的事實是,當啟用PCI訪問時,我們測出g2實例比cg1性能更差。然而,禁用它,相比cg1實例改進的性能在45%-65%之間。我們KernelMulC定制函數功能要好70%以上,基準時間在1秒內。因此,切換到G2,正確的配置將會使我們的實驗更快。
分布式貝葉斯hyperparameter優化
一旦我們優化了單節點訓練和測試操作,我們就準備解決hyperparameter優化的問題。如果你不熟悉這個概念,這里可以簡單解釋為:大多數機器學習算法的參數優化,這通常被稱為hyperparameters,以便和學習算法產生的模型參數區分。例如,在神經網絡中,我們可以考慮優化隱藏單位、學習速率等。為了優化這些,你需要訓練和測試不同的hyperparameters 組合和為你的最終模型選擇最佳的。當面對一個復雜的模型,其中每訓練一個都有時間消耗,以及有很多hyperparameters調整,執行這些詳盡的網格搜索代價非常大。幸運的是,通過考慮參數調整你可以做的比這更好。解決這種問題的一種方法是使用貝葉斯優化,算法的性能將被高斯過程建模為一個示例。高斯過程對回歸分析非常有效,但是他們擴展到大的問題時還是有困難的,當數據有限時。他們運行的很好,就像我們遇到在執行hyperparameter優化一樣。我們使用package spearmint
執行貝葉斯優化,為神經網絡訓練算法找到最好的hyperparameters。我們通過選擇一套hyperparameters使spearmint和我們的訓練算法關聯,然后使用我們GPU優化代碼訓練神經網絡。然后測試這個模型,測試度量結果用于更新hyperparameter。
我們從GPU得到高性能,但我們每臺機器只有1 -
2 GPU,所以我們想利用AWS的分布式計算能力為所有的配置來執行hyperparameter調優,如每個國際地區用不同的模型。為此,我們使用分布式任務隊列Celery
將任務發送到GPU。每個worker process聽從任務隊列,并且在一個GPU上運行。這將讓我們每天可以為所有的國際地區調優,訓練,和升級模型。
盡管Spearmint
+ Celery系統一直在運行,但是我們目前正在評估使用HTCondor或StarCluster更完整和復雜的解決方案。HTCondor可以用來管理任何Directed
Acyclic Graph (DAG)工作流。它處理輸入/輸出文件傳輸和資源管理。為了使用Condor,我們需要每個計算節點用給定的ClassAd(例如SLOT1_HAS_GPU = TRUE;STARD_ATTRS = HAS_GPU)注冊為管理人員。然后用戶可以通過配置“需求=
HAS_GPU”提交作業,這樣的工作只運行在AWS實例上,并且要有一個可用的GPU。使用Condor的主要優勢是,它還管理不同模型的訓練所需的分布式數據。Condor也允許我們以管理員身份進行Spearmint
Bayesian優化運行,而不必在每個worker運行。
另一個替代方法是使用StarCluster,它是由麻省理工大學為AWS EC2開發的一個開源集群計算框架。StarCluster以一種容錯性方式運行在Oracle Grid Engine 上(以前是 Sun Grid Engine),完全由Spearmint支持。最后,我們還在研究,將Spearmint 和 Jobman 整合以便更好地管理hyperparameter搜索工作流。下圖是使用Spearmint plus Celery、 Condor或是StarCluster的一般設置:
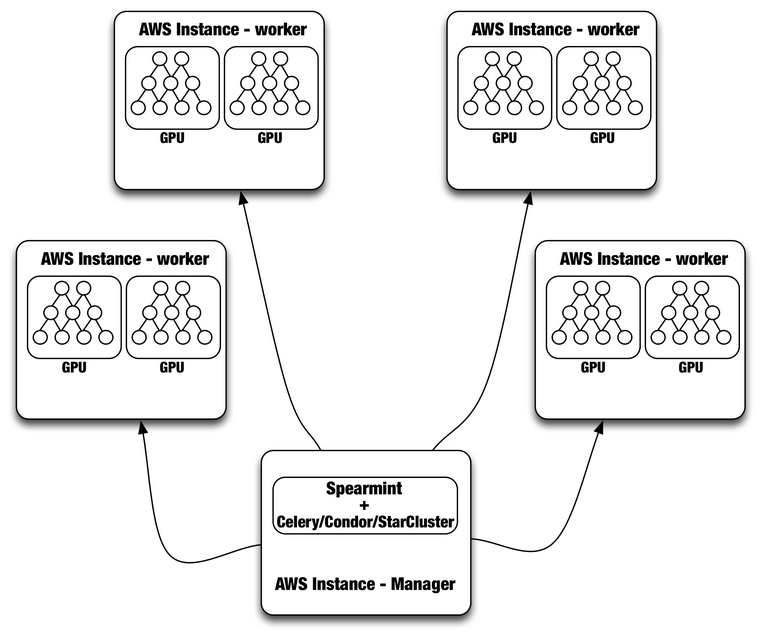
結語
使用GPU實現前沿解決方案,比如訓練大規模神經網絡需要艱苦的努力。如果你需要在自己定制的基礎設施上實現它、成本和復雜性將不可思議的。利用AWS有明顯的好處,在實例的定制和使用資源時會有一定的支持。我們希望通過分享我們的經驗來讓別人更方便開發類似應用程序。
原文鏈接: Distributed Neural Networks with GPUs in the AWS Cloud (編譯/魏偉 審校/毛夢琪)
程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


