
【編者按】深度卷積神經網絡有著廣泛的應用場景,本文對深度卷積神經網絡Deep CNNs的多GPU模型并行和數據并行框架做了詳細的分享,通過多個Worker Group實現了數據并行,同一Worker Group內多個Worker實現模型并行。框架中實現了三階段并行流水線掩蓋I/O、CPU處理時間;設計并實現了模型并行引擎,提升了模型并行計算執行效率;通過Transfer Layer解決了數據存儲訪問效率問題。此框架顯著提升了深度卷積神經網絡訓練速度,解決了當前硬件條件下訓練大模型的難題。
以下為原文:
將深度卷積神經網絡(Convolutional Neural Networks, 簡稱CNNs)用于圖像識別在研究領域吸引著越來越多目光。由于卷積神經網絡結構非常適合模型并行的訓練,因此以模型并行+數據并行的方式來加速Deep CNNs訓練,可預期取得較大收獲。Deep CNNs的單機多GPU模型并行和數據并行框架是騰訊深度學習平臺的一部分,騰訊深度學習平臺技術團隊實現了模型并行和數據并行技術加速Deep CNNs訓練,證實模型拆分對減少單GPU上顯存占用有效,并且在加速比指標上得到顯著收益,同時可以以較快速度訓練更大的深度卷積神經網絡,提升模型準確率。
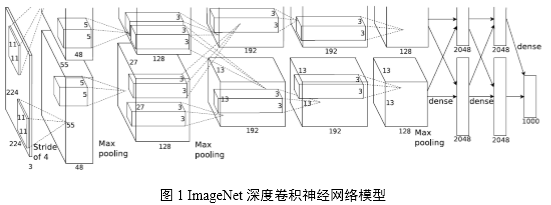
使用GPU訓練深度卷積神經網絡可取得良好的效果[1][2],自2012年使用Deep CNNs模型在ImageNet圖像分類挑戰中取得突破性成績,2013年的最佳分類結果也是由Deep CNNs模型取得。基于此,騰訊深度學習平臺技術團隊期望引入Deep CNNs來解決或優化圖像分類問題和圖像特征提取問題,以提升在相應用例場景中的效果。
隨著訓練數據集擴充、模型復雜度增加,即使采用GPU加速,在實驗過程中也存在著嚴重的性能不足,往往需要十余天時間才能達到模型的收斂,不能滿足對于訓練大規模網絡、開展更多試驗的需求
考慮到上述問題,在騰訊深度學習平臺的Deep CNNs多GPU并行訓練框架中,通過設計模型拆分方法、模型并行執行引擎和優化訪存性能的Transfer Layer,并吸收在數據并行方面設計經驗,實現了多GPU加速的模型并行和數據并行版本。
本文描述多GPU加速深度卷積神經網絡訓練系統的模型并行和數據并行實現方法及其性能優化,依托多GPU的強大協同并行計算能力,結合目標Deep CNNs模型在訓練中的并行特點,實現快速高效的深度卷積神經網絡訓練。
上述目標完成后,系統可以更快地訓練圖1中目標Deep CNNs模型。模型拆分到不同GPU上可減少對單GPU顯存占用,適用于訓練更深層次、更多參數的卷積神經網絡。
圖像作為輸入數據,其數據量龐大,且需要預處理過程,因此在Batch訓練時磁盤I/O、數據預處理工作也要消耗一定時間。經典的用計算時間掩蓋I/O時間的方法是引入流水線,因此如何設計一套有效的流水線方法來掩蓋I/O時間和CPU處理時間,以使得整體耗時只取決于實際GPU訓練時間,是一個重要問題。
模型并行是將一個完整Deep CNNs網絡的計算拆分到多個GPU上來執行而采取的并行手段,結合并行資源對模型各并行部分進行合理調度以達到模型并行加速效果是實現模型并行的關鍵步驟。
多GPU系統通過UVA(Unified Virtual Address,統一虛擬地址)技術,允許一顆GPU在kernel計算時訪問其他GPU的設備內存(即顯存),但由于遠程設備存儲訪問速度遠遠低于本地存儲訪問速度,實際性能不佳。因此在跨GPU的鄰接層數據訪問時,需要關注如何高效利用設備間數據拷貝,使所有計算數據本地化。
模型并行是:適當拆分模型到不同的計算單元上利用任務可并行性達到整個模型在計算過程中并行化效果。
如圖2所示,揭示了從單GPU訓練到多GPU模型并行訓練的相異之處,主要在于:在使用單GPU訓練的場景下,模型不進行拆分,GPU顯存上存儲整個模型;模型并行的場景下,將模型拆分到多個GPU上存儲,因此在訓練過程中每個GPU上實際只負責訓練模型的一部分,通過執行引擎的調度在一個WorkerGroup內完成對整個模型的訓練。

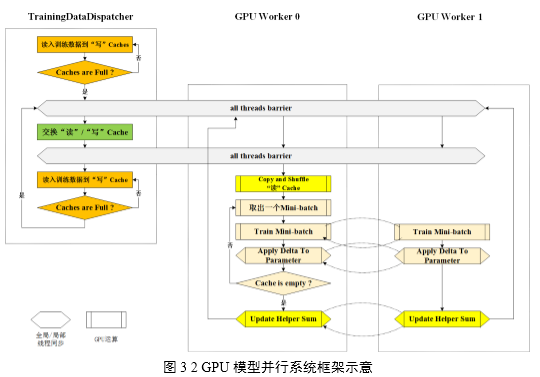
多GPU并行系統從功能上劃分為用于讀取和分發數據的Training Data Dispatcher和用于做模型并行訓練的GPU Worker,如圖3所示。訓練數據從磁盤文件讀取到CPU主存再拷貝到GPU顯存,故此設計在各Worker計算每batch數據時,由Training
Data Dispatcher從文件中讀取并分發下一batch數據,以達到用計算時間掩蓋I/O時間的設計目標。
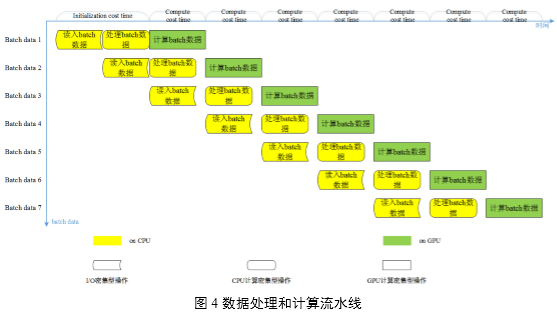
如圖4所示,總體看來,在深度卷積神經網絡訓練過程中始終是在執行一條三階段并行的流水線:計算本次batch數據――處理下次batch數據――讀入再下次batch數據。
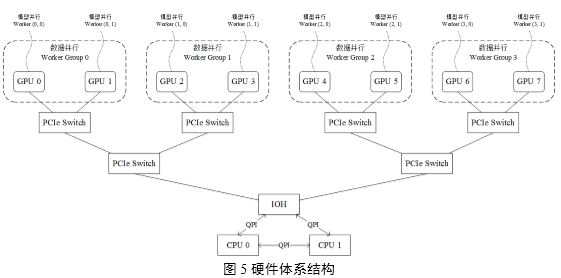
在實際生產環境中,安裝多GPU服務器的硬件體系結構如圖5所示,示例中揭示了一個8 GPU節點服務器的硬件配置,每兩個GPU Slot連接在一個GPU專用PCI槽位上再通過PCIe
Switch將GPU Slot 0,1,2,3連接在一顆CPU上,GPU Slot 4,5,6,7連接在另一顆CPU上,兩顆CPU通過IOH(Input
Output Hub)連接。
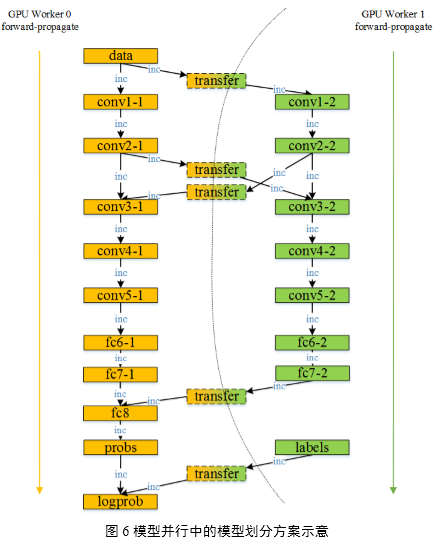
DeepCNNs網絡的層次模型實際上是一張有向無環圖(DAG圖),分配到每個模型并行Worker上的層集合,是有向無環圖的拓撲排序子集,所有子集組成整個網絡的1組模型。
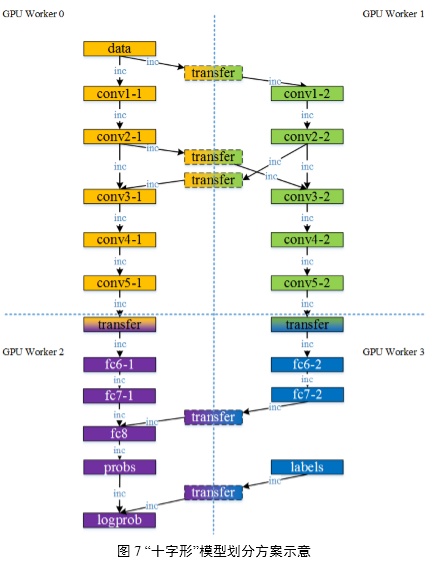
如圖7所示,描述了將模型按“十字形”劃分到4 Worker上訓練的情景,不僅拆分了模型的可并行部分,也雖然這樣的劃分在Worker 0和Worker2之間,Worker 1和Worker 3之間達到并行加速效果,卻能使得整個模型得以存儲在4 GPU上。這種模型劃分方法能夠適用于訓練超大規模網絡等特殊模型的需求。
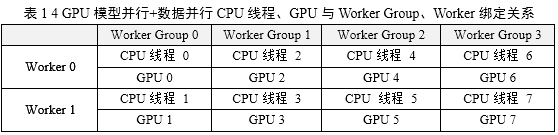
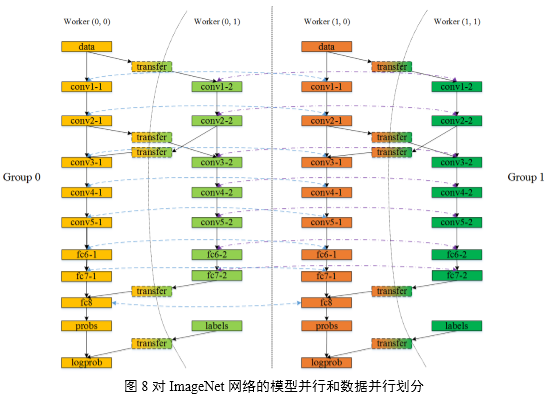
多GPU模型并行和數據并行的Deep CNNs模型replicas及劃分結構如圖8所示,在使用4 GPU的場景下,劃分了2組Worker Group用于數據并行;每個Worker
Group內劃分2個Worker用于模型并行。
訓練同樣的Deep CNNs模型,相比于單GPU,使用多GPU結合不同并行模式的加速效果如下表所示:
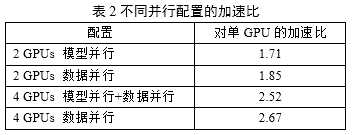
嘗試更改Deep CNNs模型,訓練一個更大的網絡,增加濾波器數目,減小步長,增加中間卷積層feature map數目,訓練時所需顯存將達到9GB以上,使用單個Tesla K20c GPU(4.8GB顯存)無法開展訓練實驗;而多GPU模型并行訓練實驗中該模型的錯誤率對比圖1模型降低2%。
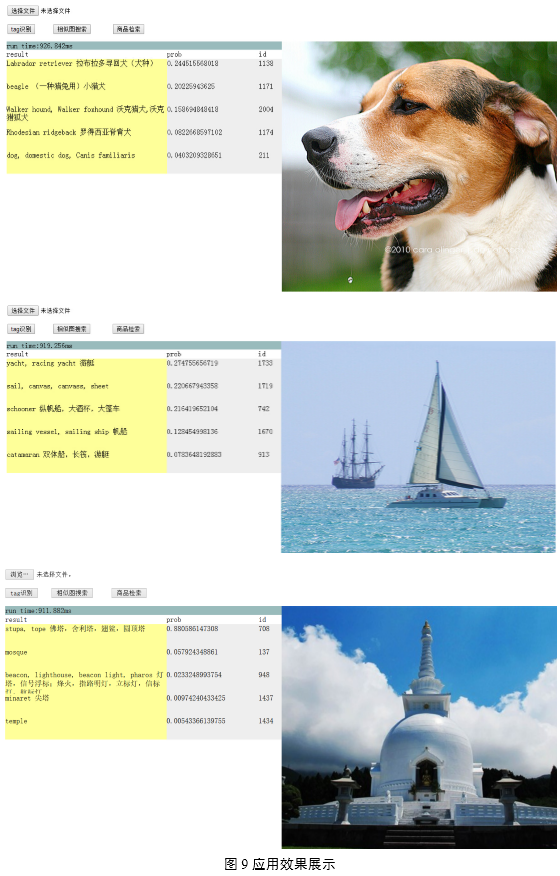
深度卷積神經網絡有著廣泛的應用場景:在圖像應用方面,Deep CNNs可應用于相似圖片檢索、圖片的自動標注和人臉識別等。在廣告圖片特征提取方面,考慮Deep
CNNs能夠很好地學習到圖像特征,我們嘗試將其用于廣告點擊率預估(Click-Through Rate Prediction, pCTR)模型中。
原文鏈接: 深度卷積神經網絡CNNs的多GPU并行框架及其在圖像識別的應用 (責編:魏偉)

上一篇 《程序員面試寶典》學習記錄6
下一篇 多平臺同步 談IE11全新功能
程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


