
伴隨云技術和應用的普及,SQL Server 2014版上會有更加明顯的“云”傾向,SQL Server 2014的技術聚焦在集成內存OLTP技術的數據庫產品、關鍵業務和性能的提升、安全和數據分析、以及混合云搭建等方面;在RedHat峰會的召開之際,RedHat宣布其企業版的OpenStack已經被企業廣泛采用,而以Canonical為代表的企業針對OpenStack和RedHat的戰爭也許剛剛開始;當下,NTP攻擊得到了長足的發展,DDoS攻擊已步入200-400Gbps時代,我們有幸采訪到了阿里云安全團隊云舒,他給我們分享了國內DDoS攻擊發展的趨勢和……
大數據催生了云計算和移動互聯的世界。2020年,企業中,將有一半以上的功能將會在云上完成。在微軟全面轉向云計算的戰略中,Cloud OS的重要性不言而喻。而在企業統一平臺的愿景上,SQL Server是最為重要一個布局。
4月11日,微軟召開微軟大數據戰略分享活動上,微軟大中華區服務器產品業務群租總經理陳利寧表示,微軟大數據的目標就是,讓用戶更加容易的把原始數據變成關鍵性決策工具。其中有三個戰略,第一是無論大小,都可以輕松訪問數據,第二是利用熟知的工具軟件,第三是提供完整、統一的數據平臺。
伴隨云技術和應用的普及,SQL Server 2014版上會更加明顯的“云”傾向。對SQL Server 2014的特點和優勢進行了詳細的介紹。主要來看,SQL Server 2014的技術聚焦在:集成內存OLTP技術的數據庫產品,關鍵業務和性能的提升,安全和數據分析,以及混合云搭建等方面。

而在SQL Server 2014之外,微軟還濃墨重彩地介紹了微軟的數據倉庫一體機。傳統來看從ERP、CRM、OA、進銷存等管理軟件的關系型數據,通過ETL、數據倉庫,最后進行到數據分析。 但事實上,關系型數據增長之外,非關系型數據、實時數據、云端數據都構成了大數據的新增長量。但對于這些數據的分析,顯然還沒有完整的技術體系。在微軟看來,現代化數據倉庫,是在基礎數據(上述四類)之上,通過數據管理與處理,數據富集與聯合查詢,最終達到BI和數據分析的過程。社交和Web分析和實時數據分析等典型場景的應用將更為寬廣。
微軟并行數據倉庫,或者說現代化數據倉庫設備一體機,則很好解決了以上問題。微軟相關負責人表示:“Hadoop自身并非所有大數據問題的終極答案。陡峭的學習曲線,緩慢低效的Hadoop生態系統,另一方面,分析前需要將HDFS遷移到倉庫,都是困難。為此,PDW(Parallel Data Warehouse Appliance))面向企業提供帶有HDinsight的Hadoop,以彌補Hadoop的不足,并實現存儲的更好擴展。”
受Red Hat峰會刺激,Canonical發布了很多關于Ubuntu Linux版本的消息,但大多數集中在OpenStack上。有點搞笑的是新聞稿宣布新的Ubuntu Linux 14.04 LTS版,但是看上去似乎關注Ubuntu OpenStack超過Linux本身。而且合作伙伴們Cisco、 Mellanox、 NTT Software對Ubuntu OpenStack也不乏贊美之辭。但話又說回來,這是有道理的,因為供應商戰場已經從核心操作系統轉移到核心的云基礎設施上面來,在這里,Canonical OpenStack得到了惠普和其他大型云提供商的有力支持。

Canonical創始人Mark Shuttleworth
Canonical創始人Mark Shuttleworth一直以來提供資金培育Ubuntu Linux,推進Ubuntu Linux / Ubuntu OpenStack融合,使之成為下一代云計算最佳基金會。
一項OpenStack基金會10月份的調查發現,55%的OpenStack工作負載使用Ubuntu Linux作為主機操作系統,CentOS為 24%; Red Hat企業級Linux為10%,剩下的占10%。鑒于Red Hat對 OpenStack的關注不斷增加,它不會滿足于這些數字。據Gigaom報道,OpenStack社區許多人并不希望Red Hat主導OpenStack,就像它主導企業級Linux一樣。不出所料,從Red Hat峰會傳來一些消息:Red Hat宣布企業級OpenStack 已經被Broad 研究所、 Midokura 以及Porto大學采用。
在軟件體系結構上,分散和集中的使用一直存在著爭議。同時,隨著網絡帶寬、硬件成本、內存的容量變大,分散式似乎大有可為。然而,從創新不斷的Google身上,我們似乎看到了一些別的東西。

這里摘抄Timothy Morgan一篇非常棒的博文――《谷歌掀開“仙女座(Andromeda)”虛擬網絡的神秘面紗》,其中還引用了Google杰出的工程師和網絡技術負責人Armin Vahdat的話:
“像Google創建的其他多數服務一樣,Andromeda網絡采用的是集中控制。順便提一下, GFS整個數據處理平臺(Hadoop啟發系統),BigTable(為市面上大量NoSQL模仿),甚至B4WAN網絡及Spanner這樣尚未被模仿的系統都使用集中控制。
我們可以看到,一個帶有P2P數據平面且邏輯集中的分級控制層服務完勝全分散式服務。Vahdat在他的keynote中寫道,“這一切都沖擊著傳統的思想,”他繼續說道:“除了上述項目,所有人都會對Google早在2002建立的大型存儲系統GFS而感到震撼。對于這個設計模式,我們是非常有信心的。我們通過審慎利用集權而不是以對等且分散的管理方式,從根本上建立一個更高效的系統。”
大數據規模和復雜度的增長給現有IT架構以及計算能力帶來了極大挑戰,機器學習領域的研究為處理未來更加龐大和復雜的數據提供了可能性,然而“機器學習”這個詞常常被誤用甚至濫用。許多初創企業,特別是在云領域,經常宣傳自身機器學習的能力,有時候,算法是不能從用戶界面看到的,因此用戶可能無法知道界面下的算法是怎樣的運行機制。用戶可能會誤以為正在使用的某個新功能或算法已經接近人工智能,然而,如果他們知道他們花錢得到的只是一些處于早期、非常不成熟的工具,只是用來構建一個決策樹的新方式,他們會怎么想?
真正的機器學習,不僅僅是存儲信息這么簡單,現實世界中信息包括語音信號、數字圖像等,通常都是高維數據,為了正確地理解這些數據,就需要對這些信息進行處理――降維,找出隱藏在高維數據中的低維結構。從數據分析的角度來說,機器學習過程就是數據挖掘的過程,機器通過挖掘出外界環境數據中潛在的規律,從而“理解”數據,理解外界環境,也就達到了“學習”的境界。機器學習還應該具有演繹、歸納和類比的能力,只需要為機器提供大前提和小前提,機器就可能給出正確的結論;而歸納能力則需要機器通過歸納求解出對事物總的概念描述,類似于人類抽象思維的能力;類比能力是演繹和推理的結合,這是機器學習最關鍵的部分,利用相似性將已存儲的信息與新事物進行匹配,檢驗相似程度,不斷更新機器已有的知識庫,以解決更多的問題。
云棲小鎮聯盟,是一群對中國發展好下一個二十年的計算產業有想法的人在一起,聯盟里既有3萬人的大公司也有3個人的創業團隊,他們篤信云計算將改變世界,志同道合的推動云計算產業在中國做起來。
第一天做云計算的時候,馬云就說,我們的目標是在云計算上長出一個比淘寶還要大的公司。將來回過頭看阿里云對中國信息產業的影響,不是我們做了什么,而是別人用我們的東西做了什么。今天在美國沒有亞馬遜這類的云服務,就不會出現像WhatsApp這樣值190億美元的公司:
1. 眾安保險,全世界第一個網絡保險牌照,第一家既沒有營業所也沒有自己IT設施的保險公司是誕生在阿里云上。今天政府能夠理解并接受一家保險公司是可以不需要買自己的計算機而放在云上,這樣的信心,是世界上其他國家做不到的。
2. 玩蟹,三個80后創造的公司,歷經兩年發展,員工從幾十人發展到上百人,賣了17億人民幣。
3. 余額寶,在成為今天的余額寶之前,也做了生死的選擇,上云還是不上?最終決定上云。沒有選擇的選擇,到后來卻發現是最好的選擇。余額寶在過去9個月的時間里可能完成了傳統公司十幾二十年都無法完成的增長。
4. Camera360,云計算互聯網讓這個幾十人的中國公司,將生意做到128個國家,而在以前這是不可能想象的。
Hadoop 是一個能夠對大量數據進行分布式處理的軟件框架。但是 Hadoop 是以一種可靠、高效、可伸縮的方式進行處理的。Hadoop 是可靠的,因為它假設計算元素和存儲會失敗,因此它維護多個工作數據副本,確保能夠針對失敗的節點重新分布處理。
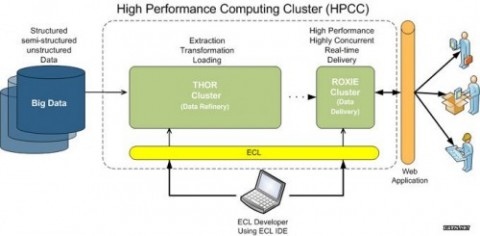
HPCC,High Performance Computing and Communications(高性能計算與通信)的縮寫。1993年,由美國科學、工程、技術聯邦協調理事會向國會提交了“重大挑戰項目:高性能計算與
通信”的報告,也就是被稱為HPCC計劃的報告,即美國總統科學戰略項目,其目的是通過加強研究與開發解決一批重要的科學與技術挑戰問題。
Storm是自由的開源軟件,一個分布式的、容錯的實時計算系統。Storm可以非常可靠的處理龐大的數據流,用于處理Hadoop的批量數據。
RapidMiner是世界領先的數據挖掘解決方案,在一個非常大的程度上有著先進技術。它數據挖掘任務涉及范圍廣泛,包括各種數據藝術,能簡化數據挖掘過程的設計和評價(詳情點擊 原文)。
近日,在第六屆中國云計算大會召開前夕,筆者有幸聯系到阿里巴巴集團安全部高級專家云舒,就國內DDoS攻擊發展趨勢、規模及阿里云安全團隊進行了簡單的了解:

CSDN:可否透露下阿里云近階段遭受的DDoS攻擊規模?
云舒:平均每月遭受數千起DDoS攻擊。
CSDN:據悉,阿里云在春節期間曾遭受到流量很大的DDoS攻擊,可否為我們簡述一下當時的戰況?
云舒:春節期間我們的OSS(Open Storage Service)遭受190Gbit/s的DDoS攻擊。攻擊者開始使用1000字節的SYN包進行攻擊,試圖在消耗CPU資源的同時堵塞網絡入口。我們的云盾系統在無人介入的情況下自動開啟防御,并發送短信報警通知。
因為攻擊效果不明顯,7分鐘之后攻擊者更換攻擊手法,使用CC攻擊。約10分鐘后,攻擊者再次更換攻擊手法,使用SYN小包進行攻擊,速率達到2000萬包/秒,試圖使交換機的交換能力達到瓶頸。整個過程持續30多分鐘,攻擊者沒有達到效果,擔心暴露而選擇了主動撤退。
CSDN:現在最普遍的DDoS攻擊類型是什么?近幾年有什么轉變?
云舒:最經典的攻擊手法SYN Flood依舊占據大頭;CC攻擊有后來居上的趨勢,因為發起容易,效果顯著;UDP攻擊屈居第三名,但卻是流量攻擊的首選,各種反射放大攻擊都屬于UDP攻擊。
MapR是知名的Hadoop供應商,最近該公司為其Hadoop發行版中添加了完整的Spark堆棧。這是一項明智之舉,更說明Spark很可能成為未來的數據處理框架。MapR也是應用Apache Spark的先驅者,周二,MapR宣布將整合Spark棧至其Hadoop版本,并將此作為與Spark初創公司Databricks合作的一部分。Spark使處理大數據工作負載變得更為便捷,也使得大數據工作負載編程變得更容易。
Spark現在如此盛行,這是因為它既做到了MapReduce可以做到的,還做到了MapReduce沒能做到的。MapReduce是傳統的Hadoop數據處理框架,它速度慢(它采用的是批處理),編程繁瑣。Spark快捷、靈活――這使得Spark可以更好的處理諸如機器學習、圖形處理和、交互式查詢類的任務――而且易于編程。Spark是用Scala寫的,不過它也支持Java,Python與R語言。
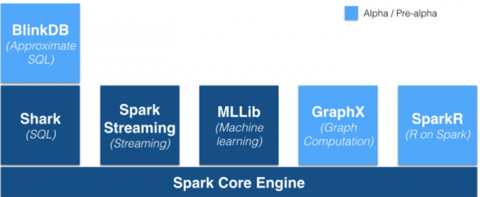
MapR的這條新聞最有趣的地方是,MapR提供了對Spark棧的全部支持――這包括Shark SQL查詢引擎(它本質上說一個更快Apache Hive)和MLLib機器學習庫――然而Cloudera卻不支持Shark。這大概是因為Cloudera還在力推它的Impala SQL查詢引擎,而MapReduce也沒有包括這個引擎。MapR一直引領交互SQL查詢項目Apache Drill的發展;此外隨著Drill的到來,MapR也添加了對HP Vertica的本地支持。
從MapR的角度,通過整合Spark這一用戶需求的功能提高了其在業界的地位(先前MapR受到的關注度是遠少于競爭對手Cloudera和Hortonworks的)。例如,MapR現在開發了自己的HBase NoSQL數據存儲,相較于其他Hadoop發行版包含的開源版本,這個數據存儲功能更齊全。
更多云計算熱點新聞: 企業實施商務智能的6個致命錯誤、 Office 365正式落地中國――移動為先,云為先、 騰訊自曝:大數據平臺的秘密、 亞馬遜AWS需解決的五項問題、 百萬用戶規模的系統如何擴展、 大數據需要軟件定義存儲、 Java線程池管理及分布式Hadoop調度框架搭建、 談DAM決策,自建還是SaaS、 “全國云計算大數據創新項目評選”征集活動正式啟動。更多云計算熱點請繼續關注CSDN云計算頻道。(文/魏偉 審校/仲浩)
以“
云計算大數據 推動智慧中國 ”為主題的
第六屆中國云計算大會 將于5月20-23日在北京國家會議中心隆重舉辦。產業觀察、技術培訓、主題論壇、行業研討,內容豐富,干貨十足。
票價折扣截止日期為4月20日,過后將恢復原價,需要購買的朋友,請抓住這最后的機會,點擊
報名!

下一篇 年入80W的96年草根站長張思聰
程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


