
在現實中,雖然很多企業都用上了新技術高科技,但很多時候,開發團隊和營運團隊總不免或多或少出現貌合神離的情況。盡管商業目標的實現與否是兩個團隊最大的驅動力,但說到底術業有專攻,雙方有側重。特別是在當今這個軟件為王的世界。
開發團隊面對的挑戰:
營運團隊面對的挑戰:
不難看出,開發部和營運部其實有著共同的目標:不斷進行改良,使企業效益最大化。但誠如現實中的一個段子:當來自金星的開發部碰上來自火星的營運部,會經常發現大家都不在服務區,無法溝通。那么該如何做,才能使這兩個企業的左膀右臂得以和諧共存?
程序延展性 ― 這是每個開發者都盼望營運者所應該了解的
開發者心聲:
我們需要花費好幾個月甚至好幾年的功夫才能開發出一個完整程序。我們費盡心思地去選擇正確的設計模式,不厭其煩地優化自己的代碼,盡最大努力保證質量。當我們再次回到代碼行間中奮筆疾書前,衷心希望營運部能從以下幾方面來好好對待我們的杰作。
首先,希望營運部能站在我們的角度來考慮問題。這次要談的是程序延展性問題。
系統性能與延展性:恰如硬幣的正反面
有時候人們會把性能和延展性混為一談,但實際上兩者是如正負極那樣有所區別的。系統性能所關心的是:例如,程序的響應時間是多少?要花費多少CPU開銷來進行一次請求應答?
另一方面,延展性所關心的是:當負載增加時,系統還能運作正常嗎?比方說,經測量我們知道響應一次請求的時間是1s,延展性就需要關系當100或1000次請求發生時,這個并發響應時間是多少s。如果1000次的響應時間都接近1s,那么這個系統的延展性是良好的;但如果響應時間隨著請求的遞增而直線遞增,那么這樣的表現是……這樣的經歷,大家應該不會陌生吧。
要構架一個可擴展的程序不是件輕易的事情,但有幾個核心原則能為成功之路做好鋪墊。第一也是最重要的,盡最大努力保持程序的狀態無關性,即程序不會在各個請求切換之間進行用戶狀態記錄。當一個部件處于狀態無關時,無論哪一個部件實例被調用,他們的作用都是相同的。這樣的好處是不論在100臺還是僅僅在1臺機器上運行,無需復雜的設置,程序都能運作良好。這是個宏偉的目標,如果你能正確解構程序,你的程序或許就會呈現最大的狀態無關性。
但是,用戶狀態有時候是需要被記錄的。例如:當你登入一個網站時,網站需要記錄你的信息來區分不同訪客。一旦你的狀態被記錄,你隨后的相關訪問信息都會被一同記錄下來。
在這種情況下,我們應該確保“粘性會話”在負載平衡器中被開啟,意思是一旦會話被建立,所有及后的請求都應該附著到同一臺機器中進行記錄。這樣做的好處是后續請求能夠清楚知道用戶的狀態,他是誰和他正在做什么;反過來,倘若分而處之,那么必須把會話復寫到不同服務器,才能讓所有機器都知道用戶的狀態了。
然而,粘性有可能受制于系統彈性。假如負責收集請求的機器宕機了,那該怎么辦?假如這需要勞煩用戶再次登錄,那對用戶體驗無疑是一次不小的打擊。有些策略是能夠幫助增強程序彈性的,不同策略對延展性的影響各有不同,有些影響是舉足輕重的。這些策略包括:
會話復制
會話復制是最常見的彈性措施。在這個模型中,當一個用戶會話發生改變時,會話對象會被序列化,然后發送到一個或多個次服務器。一旦服務器出現宕機,負載平衡器會把當前負載重定向到次服務器。在一個簡單的模型中,每個主服務器都會配備一個次服務器,這樣便可以處理更多突發中斷情況。但是一旦主次服務器同時中斷,用戶會話便也跟著丟失了。所以建議有條件的話,還是配備多個次服務器,雖然這可能會造成額外的工作量。
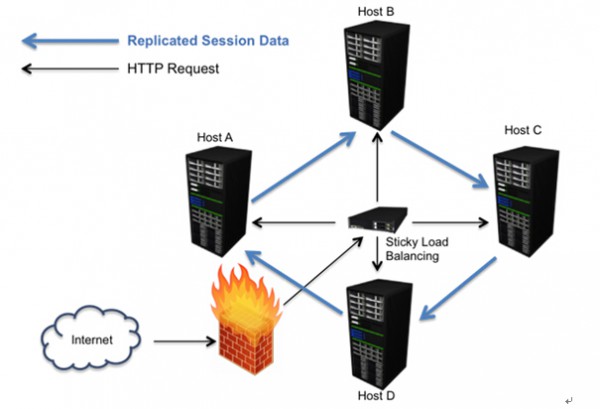
舉例來說,當你把數據復制到五個服務器時,對于每一次變更,你都需要把會話序列化,然后交叉發送到這些服務器。這樣便大大降低了系統延展性,因為需要額外的資源開銷來管理復制機。在這個情況下,我們需要營運部注意這些故障轉移規則,來協助進行必要服務器的管理。再者,我們不希望這些服務器是可變的(動態變更規模來滿足負載要求),因為在一次精確的戰略性服務器關閉措施中,需要確保會話數據不會被丟失。
下期預告:在下一篇系列文中,我們會繼續探究數據庫搜索和文件存儲會話的復制,cookies的使用以及Terracotta服務器陣列或分布式緩存。
英文出自:vmturbo

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


