
Catalyst是與Spark解耦的一個獨立庫,是一個impl-free的執(zhí)行計劃的生成和優(yōu)化框架。
目前與Spark Core還是耦合的,對此user郵件組里有人對此提出疑問,見mail。
以下是Catalyst較早時候的架構(gòu)圖,展示的是代碼結(jié)構(gòu)和處理流程。
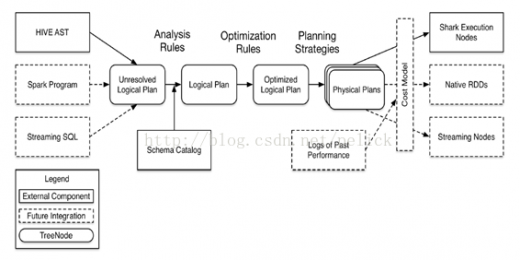
Catalyst定位
其他系統(tǒng)如果想基于Spark做一些類sql、標準sql甚至其他查詢語言的查詢,需要基于Catalyst提供的解析器、執(zhí)行計劃樹結(jié)構(gòu)、邏輯執(zhí)行計劃的處理規(guī)則體系等類體系來實現(xiàn)執(zhí)行計劃的解析、生成、優(yōu)化、映射工作。
對應上圖中,主要是左側(cè)的TreeNodelib及中間三次轉(zhuǎn)化過程中涉及到的類結(jié)構(gòu)都是Catalyst提供的。至于右側(cè)物理執(zhí)行計劃映射生成過程,物理執(zhí)行計劃基于成本的優(yōu)化模型,具體物理算子的執(zhí)行都由系統(tǒng)自己實現(xiàn)。
Catalyst現(xiàn)狀
在解析器方面提供的是一個簡單的scala寫的sql parser,支持語義有限,而且應該是標準sql的。
在規(guī)則方面,提供的優(yōu)化規(guī)則是比較基礎的(和Pig/Hive比沒有那么豐富),不過一些優(yōu)化規(guī)則其實是要涉及到具體物理算子的,所以部分規(guī)則需要在系統(tǒng)方那自己制定和實現(xiàn)(如spark-sql里的SparkStrategy)。
Catalyst也有自己的一套數(shù)據(jù)類型。
下面介紹Catalyst里幾套重要的類結(jié)構(gòu)。
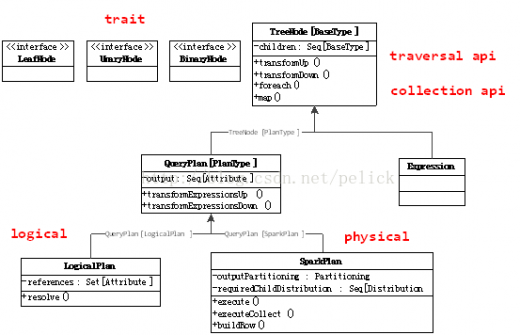
TreeNode是Catalyst執(zhí)行計劃表示的數(shù)據(jù)結(jié)構(gòu),是一個樹結(jié)構(gòu),具備一些scala collection的操作能力和樹遍歷能力。這棵樹一直在內(nèi)存里維護,不會dump到磁盤以某種格式的文件存在,且無論在映射邏輯執(zhí)行計劃階段還是優(yōu)化邏輯執(zhí)行計劃階段,樹的修改是以替換已有節(jié)點的方式進行的。
TreeNode,內(nèi)部帶一個children: Seq[BaseType]表示孩子節(jié)點,具備foreach、map、collect等針對節(jié)點操作的方法,以及transformDown(默認,前序遍歷)、transformUp這樣的遍歷樹上節(jié)點,對匹配節(jié)點實施變化的方法。
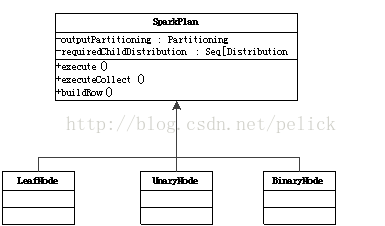
提供UnaryNode,BinaryNode, LeafNode三種trait,即非葉子節(jié)點允許有一個或兩個子節(jié)點。
TreeNode提供的是范型。
TreeNode有兩個子類繼承體系,QueryPlan和Expression。QueryPlan下面是邏輯和物理執(zhí)行計劃兩個體系,前者在Catalyst里有詳細實現(xiàn),后者需要在系統(tǒng)自己實現(xiàn)。Expression是表達式體系,后面章節(jié)都會展開介紹。
Tree的transformation實現(xiàn):
傳入PartialFunction[TreeType,TreeType],如果與操作符匹配,則節(jié)點會被結(jié)果替換掉,否則節(jié)點不會變動。整個過程是對children遞歸執(zhí)行的。
邏輯執(zhí)行計劃
QueryPlan繼承自TreeNode,內(nèi)部帶一個output: Seq[Attribute],具備transformExpressionDown、transformExpressionUp方法。
在Catalyst中,QueryPlan的主要子類體系是LogicalPlan,即邏輯執(zhí)行計劃表示。其物理執(zhí)行計劃表示由使用方實現(xiàn)(spark-sql項目中)。
LogicalPlan繼承自QueryPlan,內(nèi)部帶一個reference:Set[Attribute],主要方法為resolve(name:String): Option[NamedeExpression],用于分析生成對應的NamedExpression。
LogicalPlan有許多具體子類,也分為UnaryNode, BinaryNode, LeafNode三類,具體在org.apache.spark.sql.catalyst.plans.logical路徑下。
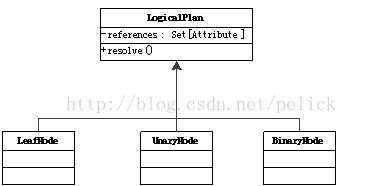
邏輯執(zhí)行計劃實現(xiàn)
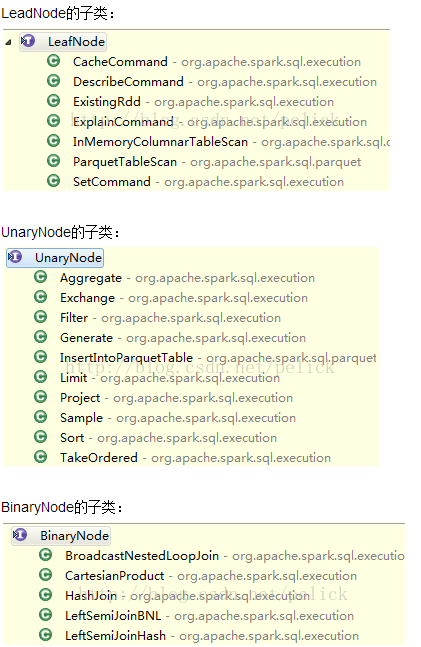
LeafNode主要子類是Command體系:
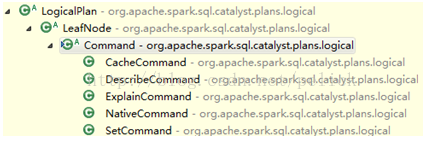
各command的語義可以從子類名字看出,代表的是系統(tǒng)可以執(zhí)行的non-query命令,如DDL。
UnaryNode的子類:
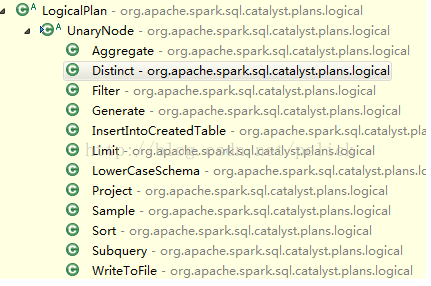
BinaryNode的子類:

物理執(zhí)行計劃
另一方面,物理執(zhí)行計劃節(jié)點在具體系統(tǒng)里實現(xiàn),比如spark-sql工程里的SparkPlan繼承體系。
物理執(zhí)行計劃實現(xiàn)
每個子類都要實現(xiàn)execute()方法,大致有以下實現(xiàn)子類(不全)。
提到物理執(zhí)行計劃,還要提一下Catalyst提供的分區(qū)表示模型。
執(zhí)行計劃映射
Catalyst還提供了一個QueryPlanner[Physical <: TreeNode[PhysicalPlan]]抽象類,需要子類制定一批strategies: Seq[Strategy],其apply方法也是類似根據(jù)制定的具體策略來把邏輯執(zhí)行計劃算子映射成物理執(zhí)行計劃算子。由于物理執(zhí)行計劃的節(jié)點是在具體系統(tǒng)里實現(xiàn)的,所以QueryPlanner及里面的strategies也需要在具體系統(tǒng)里實現(xiàn)。
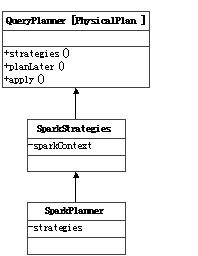
在spark-sql項目中,SparkStrategies繼承了QueryPlanner[SparkPlan],內(nèi)部制定了LeftSemiJoin, HashJoin,PartialAggregation, BroadcastNestedLoopJoin, CartesianProduct等幾種策略,每種策略接受的都是一個LogicalPlan,生成的是Seq[SparkPlan],每個SparkPlan理解為具體RDD的算子操作。
比如在BasicOperators這個Strategy里,以match-case匹配的方式處理了很多基本算子(可以一對一直接映射成RDD算子),如下:
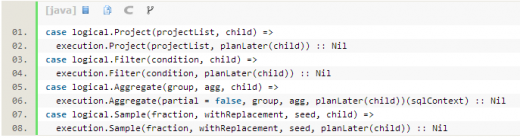
Expression,即表達式,指不需要執(zhí)行引擎計算,而可以直接計算或處理的節(jié)點,包括Cast操作,Projection操作,四則運算,邏輯操作符運算等。
具體可以參考org.apache.spark.sql.expressionspackage下的類。
凡是需要處理執(zhí)行計劃樹(Analyze過程,Optimize過程,SparkStrategy過程),實施規(guī)則匹配和節(jié)點處理的,都需要繼承RuleExecutor[TreeType]抽象類。
RuleExecutor內(nèi)部提供了一個Seq[Batch],里面定義的是該RuleExecutor的處理步驟。每個Batch代表著一套規(guī)則,配備一個策略,該策略說明了迭代次數(shù)(一次還是多次)。

Rule[TreeType <: TreeNode[_]]是一個抽象類,子類需要復寫apply(plan: TreeType)方法來制定處理邏輯。
RuleExecutor的apply(plan: TreeType): TreeType方法會按照batches順序和batch內(nèi)的Rules順序,對傳入的plan里的節(jié)點迭代處理,處理邏輯為由具體Rule子類實現(xiàn)。
Spark SQL對hive的支持是單獨的spark-hive項目,對Hive的支持包括HQL查詢、hive metaStore信息、hive SerDes、hive UDFs/UDAFs/ UDTFs,類似Shark。
只有在HiveContext下通過hive api獲得的數(shù)據(jù)集,才可以使用hql進行查詢,其hql的解析依賴的是org.apache.hadoop.hive.ql.parse.ParseDriver類的parse方法,生成Hive AST。
實際上sql和hql,并不是一起支持的。可以理解為hql是獨立支持的,能被hql查詢的數(shù)據(jù)集必須讀取自hive api。下圖中的parquet、json等其他文件支持只發(fā)生在sql環(huán)境下(SQLContext)。

Hive官方提出了Hive onSpark的JIRA。Shark結(jié)束之后,拆分為兩個方向:
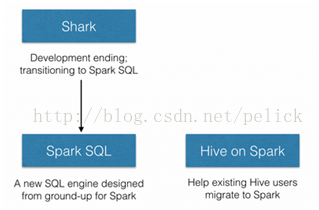
從這里看,對Hive的兼容支持將轉(zhuǎn)移到Hive on Spark上,之前Shark的經(jīng)驗將在Hive社區(qū)的這個支持上體現(xiàn)。我理解,目前SparkSQL里的那種Hive支持方式,只是為了在Spark環(huán)境下集成操縱Hive數(shù)據(jù),它的hql執(zhí)行是調(diào)用Hive客戶端Driver,跑在hadoop MR上的,本身不是Hive on Spark的實現(xiàn),只是為了使用RDD間接操作Hive數(shù)據(jù)集。
所以如果想要把現(xiàn)有Hive任務遷移到Spark上,應該使用Shark或者等待Hive on Spark。
Spark SQL里的Hive支持不是hive on spark的實現(xiàn),而更像一個讀寫Hive數(shù)據(jù)的客戶端。且其hql支持只包含hive數(shù)據(jù),與sql環(huán)境是互相獨立的。
以上兩節(jié)是Spark SQL Hive、Shark、Hive on Spark的區(qū)別和理解。
Spark SQL的核心是把已有的RDD,帶上Schema信息,然后注冊成類似sql里的”Table”,對其進行sql查詢。這里面主要分兩部分,一是生成SchemaRD,二是執(zhí)行查詢。
如果是spark-hive項目,那么讀取metadata信息作為Schema、讀取hdfs上數(shù)據(jù)的過程交給Hive完成,然后根據(jù)這倆部分生成SchemaRDD,在HiveContext下進行hql()查詢。
對于Spark SQL來說,
數(shù)據(jù)方面,RDD可以來自任何已有的RDD,也可以來自支持的第三方格式,如json file、parquet file。
SQLContext下會把帶case class的RDD隱式轉(zhuǎn)化為SchemaRDD

ExsitingRdd單例里會反射出case class的attributes,并把RDD的數(shù)據(jù)轉(zhuǎn)化成Catalyst的GenericRow,最后返回RDD[Row],即一個SchemaRDD。這里的具體轉(zhuǎn)化邏輯可以參考ExsitingRdd的productToRowRdd和convertToCatalyst方法。
之后可以進行SchemaRDD提供的注冊table操作、針對Schema復寫的部分RDD轉(zhuǎn)化操作、DSL操作、saveAs操作等等。
Row和GenericRow是Catalyst里的行表示模型
Row用Seq[Any]來表示values,GenericRow是Row的子類,用數(shù)組表示values。Row支持數(shù)據(jù)類型包括Int, Long, Double, Float, Boolean, Short, Byte, String。支持按序數(shù)(ordinal)讀取某一個列的值。讀取前需要做isNullAt(i: Int)的判斷。
各自都有Mutable類,提供setXXX(i: int, value: Any)修改某序數(shù)上的值。

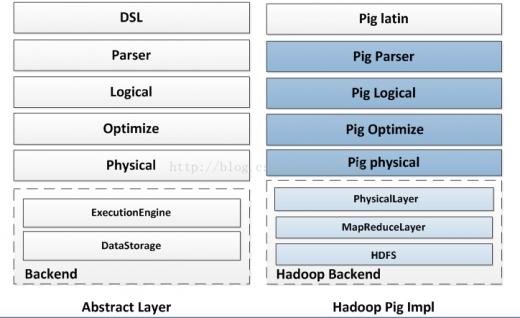
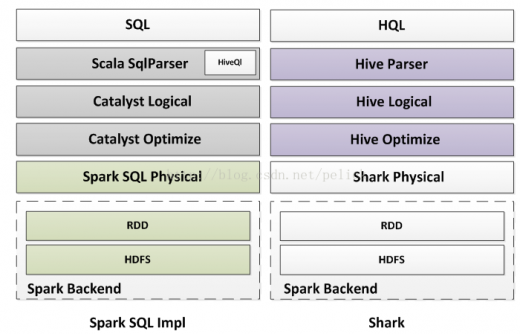
下圖大致對比了Pig,Spark SQL,Shark在實現(xiàn)層次上的區(qū)別,僅做參考。
SQLContext里對sql的一個解析和執(zhí)行流程:
1. 第一步parseSql(sql: String),simple sql parser做詞法語法解析,生成LogicalPlan。
2. 第二步analyzer(logicalPlan),把做完詞法語法解析的執(zhí)行計劃進行初步分析和映射,
目前SQLContext內(nèi)的Analyzer由Catalyst提供,定義如下:
new Analyzer(catalog, EmptyFunctionRegistry, caseSensitive =true)
catalog為SimpleCatalog,catalog是用來注冊table和查詢relation的。
而這里的FunctionRegistry不支持lookupFunction方法,所以該analyzer不支持Function注冊,即UDF。
Analyzer內(nèi)定義了幾批規(guī)則:
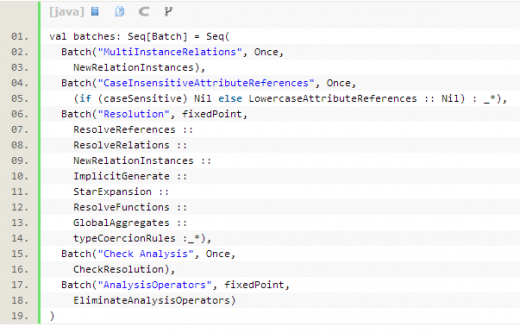
3. 從第二步得到的是初步的logicalPlan,接下來第三步是optimizer(plan)。
Optimizer里面也是定義了幾批規(guī)則,會按序?qū)?zhí)行計劃進行優(yōu)化操作。
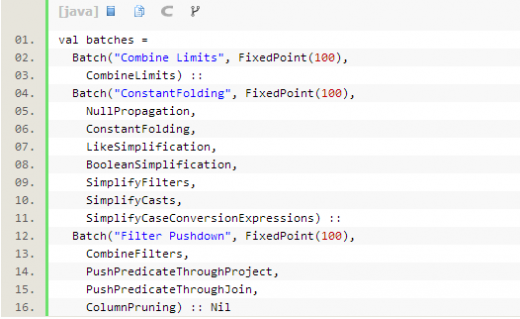
4. 優(yōu)化后的執(zhí)行計劃,還要丟給SparkPlanner處理,里面定義了一些策略,目的是根據(jù)邏輯執(zhí)行計劃樹生成最后可以執(zhí)行的物理執(zhí)行計劃樹,即得到SparkPlan。
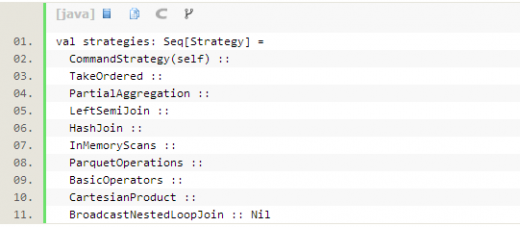
5. 在最終真正執(zhí)行物理執(zhí)行計劃前,最后還要進行兩次規(guī)則,SQLContext里定義這個過程叫prepareForExecution,這個步驟是額外增加的,直接new
RuleExecutor[SparkPlan]進行的。

6. 最后調(diào)用SparkPlan的execute()執(zhí)行計算。這個execute()在每種SparkPlan的實現(xiàn)里定義,一般都會遞歸調(diào)用children的execute()方法,所以會觸發(fā)整棵Tree的計算。
內(nèi)存列存儲
SQLContext下cache/uncache table的時候會調(diào)用列存儲模塊。
該模塊借鑒自Shark,目的是當把表數(shù)據(jù)cache在內(nèi)存的時候做行轉(zhuǎn)列操作,以便壓縮。
實現(xiàn)類
InMemoryColumnarTableScan類是SparkPlan LeafNode的實現(xiàn),即是一個物理執(zhí)行計劃。傳入一個SparkPlan(確認了的物理執(zhí)行計)和一個屬性序列,內(nèi)部包含一個行轉(zhuǎn)列、觸發(fā)計算并cache的過程(且是lazy的)。
ColumnBuilder針對不同的數(shù)據(jù)類型(boolean, byte, double, float, int, long, short, string)由不同的子類把數(shù)據(jù)寫到ByteBuffer里,即包裝Row的每個field,生成Columns。與其對應的ColumnAccessor是訪問column,將其轉(zhuǎn)回Row。
CompressibleColumnBuilder和CompressibleColumnAccessor是帶壓縮的行列轉(zhuǎn)換builder,其ByteBuffer內(nèi)部存儲結(jié)構(gòu)如下
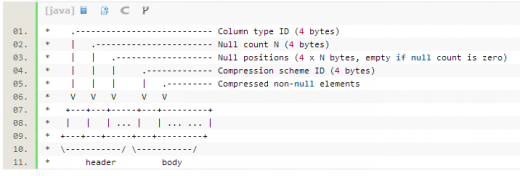
CompressionScheme子類是不同的壓縮實現(xiàn)
都是scala實現(xiàn)的,未借助第三方庫。不同的實現(xiàn),指定了支持的column data類型。在build()的時候,會比較每種壓縮,選擇壓縮率最小的(若仍大于0.8就不壓縮了)。
這里的估算邏輯,來自子類實現(xiàn)的gatherCompressibilityStats方法。
Cache邏輯
cache之前,需要先把本次cache的table的物理執(zhí)行計劃生成出來。
在cache這個過程里,InMemoryColumnarTableScan并沒有觸發(fā)執(zhí)行,但是生成了以InMemoryColumnarTableScan為物理執(zhí)行計劃的SparkLogicalPlan,并存成table的plan。
其實在cache的時候,首先去catalog里尋找這個table的信息和table的執(zhí)行計劃,然后會進行執(zhí)行(執(zhí)行到物理執(zhí)行計劃生成),然后把這個table再放回catalog里維護起來,這個時候的執(zhí)行計劃已經(jīng)是最終要執(zhí)行的物理執(zhí)行計劃了。但是此時Columner模塊相關(guān)的轉(zhuǎn)換等操作都是沒有觸發(fā)的。
真正的觸發(fā)還是在execute()的時候,同其他SparkPlan的execute()方法觸發(fā)場景是一樣的。
Uncache邏輯
UncacheTable的時候,除了刪除catalog里的table信息之外,還調(diào)用了InMemoryColumnarTableScan的cacheColumnBuffers方法,得到RDD集合,并進行了unpersist()操作。cacheColumnBuffers主要做了把RDD每個partition里的ROW的每個Field存到了ColumnBuilder內(nèi)。
UDF(暫不支持)
如前面對SQLContext里Analyzer的分析,其FunctionRegistry沒有實現(xiàn)lookupFunction。
在spark-hive項目里,HiveContext里是實現(xiàn)了FunctionRegistry這個trait的,其實現(xiàn)為HiveFunctionRegistry,實現(xiàn)邏輯見org.apache.spark.sql.hive.hiveUdfs
Parquet支持
待整理
http://parquet.io/
Specific Docs and Codes:
https://github.com/apache/incubator-parquet-format
https://github.com/apache/incubator-parquet-mr
http://www.slideshare.net/julienledem/parquet-hadoop-summit-2013
JSON支持
SQLContext下,增加了jsonFile的讀取方法,而且目前看,代碼里實現(xiàn)的是hadoop textfile的讀取,也就是這份json文件應該是在HDFS上的。具體這份json文件的載入,InputFormat是TextInputFormat,key class是LongWritable,value class是Text,最后得到的是value部分的那段String內(nèi)容,即RDD[String]。
除了jsonFile,還支持jsonRDD,例子:
http://spark.apache.org/docs/latest/sql-programming-guide.html#json-datasets
讀取json文件之后,轉(zhuǎn)換成SchemaRDD。JsonRDD.inferSchema(RDD[String])里有詳細的解析json和映射出schema的過程,最后得到該json的LogicalPlan。
Json的解析使用的是FasterXML/jackson-databind庫,GitHub地址,wiki
把數(shù)據(jù)映射成Map[String, Any]
Json的支持豐富了Spark SQL數(shù)據(jù)接入場景。
JDBC支持
Jdbc support branchis under going
SQL92
Spark SQL目前的SQL語法支持情況見SqlParser類。目標是支持SQL92??
1. 基本應用上,sql server 和oracle都遵循sql 92語法標準。
2. 實際應用中大家都會超出以上標準,使用各家數(shù)據(jù)庫廠商都提供的豐富的自定義標準函數(shù)庫和語法。
3. 微軟sql server的sql 擴展叫T-SQL(Transcate SQL).
4. Oracle 的sql 擴展叫PL-SQL.
大家可以跟進社區(qū)郵件列表,后續(xù)待整理。
http://apache-spark-developers-list.1001551.n3.nabble.com/sparkSQL-thread-safe-td7263.html
http://apache-spark-user-list.1001560.n3.nabble.com/Supported-SQL-syntax-in-Spark-SQL-td9538.html
總結(jié)
以上整理了對Spark SQL各個模塊的實現(xiàn)情況,代碼結(jié)構(gòu),執(zhí)行流程以及自己對Spark SQL的理解。
原文鏈接: 整理對Spark SQL的理解 (責編/魏偉)
 免費訂閱“CSDN云計算”微信公眾號,實時掌握第一手云中消息!
免費訂閱“CSDN云計算”微信公眾號,實時掌握第一手云中消息!
CSDN作為國內(nèi)最專業(yè)的云計算服務平臺,提供云計算、大數(shù)據(jù)、虛擬化、數(shù)據(jù)中心、OpenStack、CloudStack、Hadoop、Spark、機器學習、智能算法等相關(guān)云計算觀點,云計算技術(shù),云計算平臺,云計算實踐,云計算產(chǎn)業(yè)資訊等服務。

程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學習,原版權(quán)很多不明,如有侵權(quán)請聯(lián)系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權(quán)所有


