
【編者按】大數據為Pinterest打造了線上最豐富的興趣集,在網站的配置和運營中發揮著重要的作用,為了迅速搭建大數據平臺,Pinterest將單個集群Hadoop基礎設施升級為一個通用的自服務平臺。近日,Pinterest在該公司的博客上公布了這個平臺的打造過程。

免費訂閱“CSDN大數據”微信公眾號,實時了解最新的大數據進展!
CSDN大數據,專注大數據資訊、技術和經驗的分享和討論,提供Hadoop、Spark、Imapala、Storm、HBase、MongoDB、Solr、機器學習、智能算法等相關大數據觀點,大數據技術,大數據平臺,大數據實踐,大數據產業資訊等服務。
大數據在Pinterest中扮演著重要的角色。系統中有300多億Pins,我們打造了線上最豐富的興趣集。打造個性化搜索引擎的一個挑戰是擴展數據基礎設施以遍歷興趣圖譜,進而提取每一Pin的內容和意圖。
目前我們每天更新20TB數據,S3每天會更新大概10TB數據。我們使用Hadoop處理這些數據,Hadoop使得我們可以通過Related Pins、Guided Search及image processing等功能將最相關和最新的內容呈現給 Pinners。Hadoop每天可以幫助我們執行數千個度量,探測嚴格實驗條件下的用戶變化并進行分析。
為了迅速搭建大數據應用,我們將單個集群Hadoop基礎設施升級為一個通用的自服務平臺。

為Hadoop搭建一個自服務平臺
盡管Hadoop是一個強大的處理和存儲系統,但是它還不是一項即插即用的技術。因為Hadoop沒有云計算和彈性計算,也不面向非技術用戶,所以最初的Hadoop設計無法作為一個自服務系統。好在很多Hadoop庫、Hadoop應用和服務提供商針對這些局限提供了解決方案。在選擇解決方案前,我們先討論了我們的Hadoop設置需求。
1. 多租戶隔離:MapReduce上有許多需求和配置不同應用程序,開發者應該在不影響他人工作的前提下優化自己的工作。
2. 彈性:批處理通常需要突發性能來支持實驗開發。一個理想的配置中,我們可以擴展至數千個節點集群,然后在不導致任何中斷和數據損失的情況下減少規模。
3. 多集群支持:盡管我們可以水平擴展單個Hadoop集群,我們發現:很難獲得理想的隔離性和彈性;諸如隱私、安全、成本分攤等商業需求使多集群支持更為實用。
4. 支持臨時集群:用戶應當可以在需要使用集群時獲得集群,并可以隨時退出集群。集群在合理的時間范圍內存在,并可以在不需要手動配置的情況下全面支持所有的Hadoop工作。
5. 易于軟件包部署:從OS和Hadoop層到具體業務腳層面,我們需要為用戶提供定制化的接口。
6. 共享數據存儲:Hadoop也應可以訪問其它集群產生的數據。
7. 訪問控制層:和其它的服務導向的系統一樣,我們需要快速添加和修改訪問(如非SSH關鍵詞)。理想情況下,我們可以和現有認證(如通過OAUTH)整合。
權衡和實施
總結出需求后,我們在一系列自行開發的、開源的和商業專有的解決方案中尋找符合我們需求的解決方案。
解耦計算和存儲:為加快處理速度,傳統的MapReduce采用數據本地化。實際中,我們發現網絡I/O(我們使用的是S3)并沒有比磁盤I/O慢很多。通過支付網絡I/O的邊際成本和將計算從存儲分離,我們很容易的實現我們的自服務Hadoop平臺的許多需求。例如,因為我們不再需要考慮加載或同步數據,所以多集群支持變得很容易,任何現有或將來的集群都可以通過一個共享文件系統使用數據。不需要擔心數據意味著更簡單的操作,這是因為我們可以在不丟失任何工作的情況下進行硬復位或丟棄一個集群,遷移到另一個集群。這也意味著我們可以使用動態的節點,因此我們可以支付低廉的計算機費用,不擔心損失任何持久性數據。
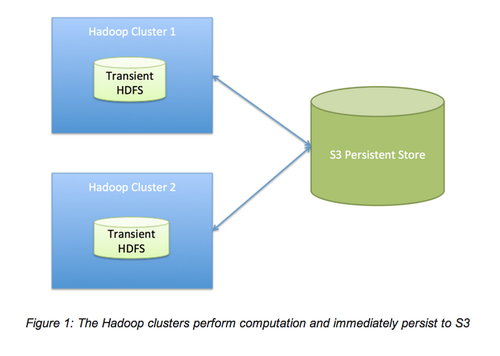
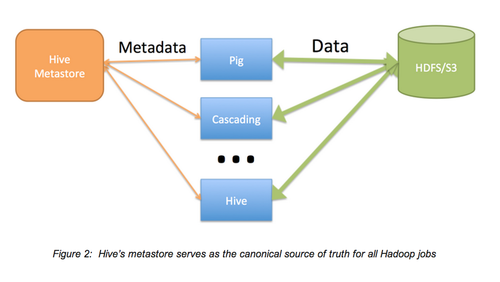
集中式Hive元存儲作為解決方案:我們大部分的工作都選用Hadoop,這是因為SQL接口很簡單,業界對SQL接口也很熟悉。隨著時間的推移,我們發現使用元存儲作為Hadoop工作的數據目錄時,Hive還會帶來額外的好處。Hive很像其它的SQL工具,它提供了諸如“show tables”,“describe table”和“show partitions”的功能。這個接口比在目錄中決定生成文件的清單文件簡潔的多,也快的多,一致性也更好,這是因為MySQL數據庫支持著這個接口。S3的清單文件很慢,S3不支持移動,還有一致性的問題。因為我們依賴于S3,所以Hive的這些特性顯得更重要。
我們用與現有磁盤數據保持Hive元數據一致性的方式排列工作(是Hive,Cascading,Hadoop Steaming還是其它的)。因此,我們可以在多集群和多工作流更新磁盤數據,無需擔心用戶可能獲得部分數據。
多層包/配置:Hadoop應用間差異很大,每個應用都可能有獨特的需求和依賴項。我們需要一種靈活的、可以權衡可定制性和快速配置/速度的方法。
我們采用一種三層的方法來管理依賴項,這種方法可以將產生、調用一個千節點集群的時間從45分鐘減到5分鐘。
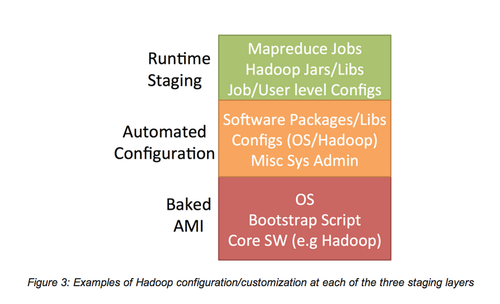
1. Baking AMI
對于那些較大的、需要花一段時間安裝的依賴項,我們將他們預安裝。其中包括我們為了國際化所采用的Hadoop庫和NLP庫包。我們將這一過程稱為“baking an AMI”。不幸的是,很多Hadoop服務供應商尚不支持這種方法。
2. 自動化配置(無管理的Puppet)
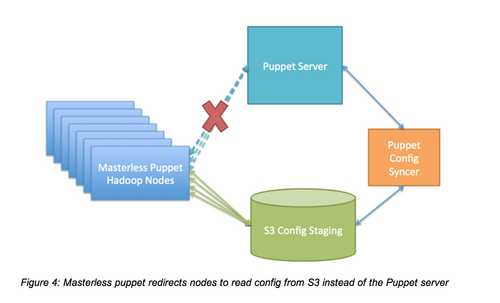
我們大部分的定制化服務是使用Puppet管理的。在引導程序階段,我們的集群在每個節點都安裝和配置Puppet,僅需幾分鐘的時間,Puppet就可以將我們的節點和Puppet配置指定的依賴項匹配。
目前,Puppet主要的局限性如下:當我們在生產系統添加新節點時,這些新節點會自動聯系Puppet管理,推翻新配置,這常常會覆蓋主節點,進而導致錯誤。為了避免這種錯誤,我們允許Puppet客戶端從S3獲取配置,設置一個負責同步S3配置和Puppet管理的服務,從而將Puppet客戶端設置為“無管理”。
3. 運行階段(在S3上)
MapReduce工作間發生的大部分定制化服務都涉及jars,工作配置和自定義代碼。開發組需要可以在開發環境中修改這些依賴項,并且在不影響其他工作的前提下使這些依賴項在我們的任意一個Hadoop集群中可用。為了權衡靈活性、速度和隔離性,我們為S3上的每個開發者創建了一個隔離的工作目錄。現在,當一個工作執行時,一個工作目錄面向一個開發者,工作路徑的依賴項直接從S3獲得。
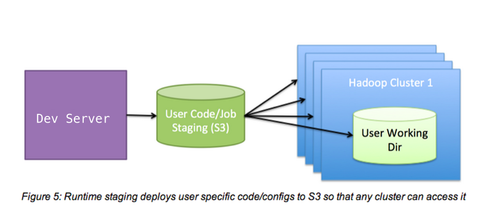
執行抽象層
先前,我們使用亞馬遜的Elastic MapReduce(EMR)運行我們的Hadoop工作。EMR和S3、Spot實例運行的很好,通常也很穩定。但當我們擴展到幾百個節點時,EMR變得沒那么穩定,我們遇到了EMR的局限。我們在EMR上搭建了很多應用,以至于我們很難遷移到一個新系統。我們也不知道更換到哪種系統,因為EMR的一些細微差異會導致實際工作邏輯差異。為了試驗其它類型的Hadoop,我們實施了一個執行接口,將所有的EMR特定邏輯都遷移到EMR執行接口。 這個接口實施了一系列方法,如“run_raw_hive_query(query_str)” 和 “run_java_job(class_path)”。這使得我們具有在幾種Hadoop和Hadoop服務供應商上實驗的靈活性,并可以以最小的停機時間逐漸遷移。
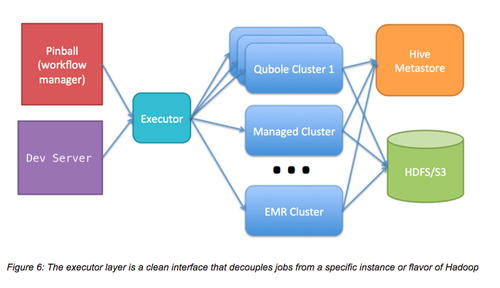
最終采用Qubole
最終我們決定將我們的Hadoop工作遷移到Qubole,Quble是Hadoop服務市場的新秀。考慮到目前我們的規模下EMR不再穩定,我們必須快速遷移到一個良好支持AWS(特別是spot實例)和S3的供應商。Qubole支持AWS/S3,并且起步簡單。在審核Qubole,并將其性能和幾個候選者(包括管理集群)比較后,我們選擇了Qubole,原因如下:
總的來說,使用Qubole對我們而言是一個正確的決定,Qubole團隊的技術和實施工作深深地打動了我們。從去年開始,Qubole證明了其在拍字節規模的穩定性,相比EMR,為我們提高了30%~60%的吞吐量。非技術用戶也很容易上手Qubole。
我們目前的狀態
在我們當下的配置下,Hadoop是一項應用在多組織、操作費用低的靈活服務。我們有100多個常規Mapreduce用戶,他們每天通過Qubole網絡接口、ad-hoc工作和計劃工作流運行著2000多個工作。
我們有6個Hadoop集群,他們由3000多個節點組成,開發者可以在幾分鐘內選擇創建自己的Hadoop集群。我們每天生成200億日志信息,處理大概1拍字節的數據。
我們也在試驗者管理Hadoop集群,其中包括Hadoop2,不過目前,使用諸如S3和Qubole的云服務對我們而言是正確的選擇,因為它們將我們從Hadoop的操作開銷中解放出來,使我們可以專注于大數據應用的工程工作。
原文鏈接: Powering big data at Pinterest(翻譯/仁君 責編/仲浩)

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


