
【編者按】Spark是一個基于內存計算的開源集群計算系統,目的是更快速的進行數據分析。Spark由加州伯克利大學AMP實驗室Matei為主的小團隊使用Scala開發開發,其核心部分的代碼只有63個Scala文件,非常輕量級。 Spark 提供了與 Hadoop 相似的開源集群計算環境,但基于內存和迭代優化的設計,Spark 在某些工作負載表現更優秀。
在2014上半年,Spark開源生態系統得到了大幅增長,已成為大數據領域最活躍的開源項目之一,當下已活躍在Hortonworks、IBM、Cloudera、MapR和Pivotal等眾多知名大數據公司。那么Spark究竟以什么吸引了如此多的關注,這里我們看向Dzone上的6個總結。

免費訂閱“CSDN大數據”微信公眾號,實時了解最新的大數據進展!
CSDN大數據,專注大數據資訊、技術和經驗的分享和討論,提供Hadoop、Spark、Imapala、Storm、HBase、MongoDB、Solr、機器學習、智能算法等相關大數據觀點,大數據技術,大數據平臺,大數據實踐,大數據產業資訊等服務。
以下為譯文
1. 輕量級快速處理。著眼大數據處理,速度往往被置于第一位,我們經常尋找能盡快處理我們數據的工具。Spark允許Hadoop集群中的應用程序在內存中以100倍的速度運行,即使在磁盤上運行也能快10倍。Spark通過減少磁盤IO來達到性能提升,它們將中間處理數據全部放到了內存中。
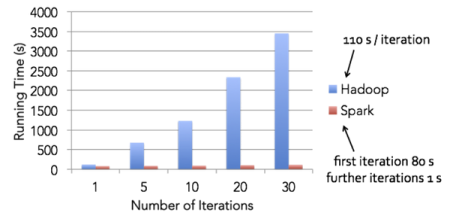
Spark使用了RDD(Resilient Distributed Dataset)的理念,這允許它可以透明的內存中存儲數據,只在需要時才持久化到磁盤。這種做法大大的減少了數據處理過程中磁盤的讀寫,大幅度的降低了所需時間。
2. 易于使用,Spark支持多語言。Spark允許Java、Scala及Python,這允許開發者在自己熟悉的語言環境下進行工作。它自帶了80多個高等級操作符,允許在shell中進行交互式查詢。
3. 支持復雜查詢。在簡單的“map”及“reduce”操作之外,Spark還支持SQL查詢、流式查詢及復雜查詢,比如開箱即用的機器學習機圖算法。同時,用戶可以在同一個工作流中無縫的搭配這些能力。
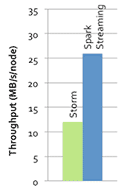
4. 實時的流處理。對比MapReduce只能處理離線數據,Spark支持實時的流計算。Spark依賴Spark Streaming對數據進行實時的處理,當然在YARN之后Hadoop也可以借助其他的工具進行流式計算。對于Spark Streaming,Cloudera的評價是:
5. 可以與Hadoop和已存Hadoop數據整合。Spark可以獨立的運行,除了可以運行在當下的YARN集群管理之外,它還可以讀取已有的任何Hadoop數據。這是個非常大的優勢,它可以運行在任何Hadoop數據源上,比如HBase、HDFS等。這個特性讓用戶可以輕易遷移已有Hadoop應用,如果合適的話。
6. 活躍和無限壯大的社區。Spark起源于2009年,當下已有超過50個機構250個工程師貢獻過代碼,和去年六月相比,代碼行數幾乎擴大三倍,這是個令人艷羨的增長。
相關鏈接
原文鏈接:
6 sparkling features of Apache Spark!(編譯/仲浩 審校/魏偉)

程序員人生,我編程,我富裕,記住wfuyu網,php教程,php學習,php手冊,CMS模版制作
聲明:本站大部分內容是作者原創,少部分收集于互聯網供大家一起學習,原版權很多不明,如有侵權請聯系本站,謝謝!
粵ICP備14040726號-1?? 2015-2020 程序員人生 版權所有


