
 免費(fèi)訂閱“CSDN大數(shù)據(jù)”微信公眾號(hào),實(shí)時(shí)了解最新的大數(shù)據(jù)進(jìn)展!
免費(fèi)訂閱“CSDN大數(shù)據(jù)”微信公眾號(hào),實(shí)時(shí)了解最新的大數(shù)據(jù)進(jìn)展!
CSDN大數(shù)據(jù),專注大數(shù)據(jù)資訊、技術(shù)和經(jīng)驗(yàn)的分享和討論,提供Hadoop、Spark、Imapala、Storm、HBase、MongoDB、Solr、機(jī)器學(xué)習(xí)、智能算法等相關(guān)大數(shù)據(jù)觀點(diǎn),大數(shù)據(jù)技術(shù),大數(shù)據(jù)平臺(tái),大數(shù)據(jù)實(shí)踐,大數(shù)據(jù)產(chǎn)業(yè)資訊等服務(wù)。
以下為原文:
最近我在做流式實(shí)時(shí)分布式計(jì)算系統(tǒng)的架構(gòu)設(shè)計(jì),而正好又要參見CSDN博文大賽的決賽。本來想就寫Spark源碼分析的文章吧。但是又想畢竟是決賽,要拿出一些自己的干貨出來,僅僅是源碼分析貌似分量不夠。因此,我將最近一直在做的系統(tǒng)架構(gòu)的思路整理出來,形成此文。為什么要參考Storm和Spark,因?yàn)闆]有參照效果可能不會(huì)太好,尤其是對(duì)于Storm和Spark由了解的同學(xué)來說,可能通過對(duì)比,更能體會(huì)到每個(gè)具體實(shí)現(xiàn)背后的意義。
本文對(duì)流式系統(tǒng)出現(xiàn)的背景,特點(diǎn),數(shù)據(jù)HA,服務(wù)HA,節(jié)點(diǎn)間和計(jì)算邏輯間的消息傳遞,存儲(chǔ)模型,計(jì)算模型,與生產(chǎn)環(huán)境融合都有涉及。希望對(duì)大家的工作和學(xué)習(xí)有所幫助。
正文開始:
流式實(shí)時(shí)分布式計(jì)算系統(tǒng)在互聯(lián)網(wǎng)公司占有舉足輕重的地位,尤其在在線和近線的海量數(shù)據(jù)處理上。在線系統(tǒng)負(fù)責(zé)處理在線請(qǐng)求,因此低延時(shí)高可靠是核心指標(biāo)。在線系統(tǒng)是互聯(lián)網(wǎng)公司的核心,系統(tǒng)的好壞直接影響了流量,而流量對(duì)互聯(lián)網(wǎng)公司來說意味著一切。在線系統(tǒng)使用的數(shù)據(jù)是來自于后臺(tái)的計(jì)算系統(tǒng)產(chǎn)生的。
對(duì)于在線(區(qū)別于響應(yīng)互聯(lián)網(wǎng)用戶請(qǐng)求的在線系統(tǒng),這個(gè)在線系統(tǒng)主要是內(nèi)部使用的,也就是說并不直接服務(wù)于互聯(lián)網(wǎng)用戶)/近線系統(tǒng)來說,處理的是線上產(chǎn)生的數(shù)據(jù),比如在線系統(tǒng)產(chǎn)生的日志,記錄用戶行為的數(shù)據(jù)庫(kù)等,因此近線系統(tǒng)也需要低延時(shí)高可靠的處理海量數(shù)據(jù)。對(duì)于那些時(shí)效性很強(qiáng)的數(shù)據(jù),比如新聞熱點(diǎn),電商的促銷,微博熱詞等都需要在很短的時(shí)間內(nèi)完成數(shù)據(jù)處理以供在線系統(tǒng)使用。
而處理這些海量數(shù)據(jù)的,就是實(shí)時(shí)流式計(jì)算系統(tǒng)。Spark是實(shí)時(shí)計(jì)算的系統(tǒng),支持流式計(jì)算,批處理和實(shí)時(shí)查詢。它使用一個(gè)通用的stack解決了很多問題,畢竟任何公司都想要Unified的平臺(tái)去處理遇到的問題,可以減少開發(fā)和維護(hù)的人力成本和部署平臺(tái)的物力成本。除了Spark,流式計(jì)算系統(tǒng)最有名的就是Twitter的Storm和Yahoo的S4(其實(shí)Spark的流式計(jì)算還是要弱于Storm的,個(gè)人認(rèn)為互聯(lián)網(wǎng)公司對(duì)于Storm的部署還是多于Spark的)。
本文主要探討流式計(jì)算系統(tǒng)的設(shè)計(jì)要點(diǎn),并且通過對(duì)Spark和Storm的實(shí)現(xiàn)來給出實(shí)例。通過對(duì)于系統(tǒng)設(shè)計(jì)要點(diǎn)的梳理,也可以幫助我們更好的學(xué)習(xí)這些系統(tǒng)的實(shí)現(xiàn)。最后,看一下國(guó)內(nèi)互聯(lián)網(wǎng)公司對(duì)于這些流式系統(tǒng)的應(yīng)用(僅限于公開發(fā)表的內(nèi)容)。
現(xiàn)在很多公司每天都會(huì)產(chǎn)生數(shù)以TB級(jí)的大數(shù)據(jù),如何對(duì)這些數(shù)據(jù)進(jìn)行挖掘,分析成了很重要的課題。比如:
流式實(shí)時(shí)分布式計(jì)算系統(tǒng)就是要解決上述問題的。這些系統(tǒng)的共同特征是什么?
Hadoop定義了Map和Reduce,使得應(yīng)用者只需要實(shí)現(xiàn)MR就可以實(shí)現(xiàn)數(shù)據(jù)處理。而流式系統(tǒng)的特點(diǎn),允許它們可以進(jìn)行更加具體一些的原語設(shè)計(jì)。流式的數(shù)據(jù)的特點(diǎn)就是數(shù)據(jù)時(shí)源源不斷進(jìn)入系統(tǒng)的,而這些數(shù)據(jù)的處理一般都需要幾個(gè)階段。拿普通的日志處理來說,我們可能僅僅關(guān)注Error的日志,那么系統(tǒng)的第一個(gè)計(jì)算邏輯就是進(jìn)行filer。接下來可能需要對(duì)這個(gè)日志進(jìn)行分段,分段后可能交給不同的規(guī)則處理器進(jìn)行處理。因此,數(shù)據(jù)處理一般是分階段的,可以說是一個(gè)有向無環(huán)圖,或者說是一個(gè)拓?fù)洹?shí)際上,Spark抽象出的運(yùn)算邏輯就是由RDD(Resilient Distributed Dataset)構(gòu)成DAG(Directed Acyclic Graph),而Storm則有Spout和Blot構(gòu)成Topology(拓?fù)洌?/p>
Spark的設(shè)計(jì)
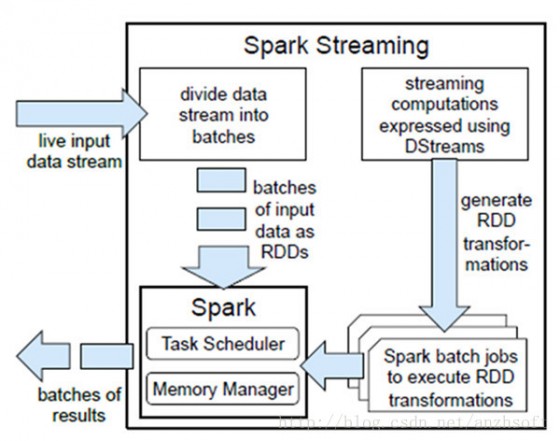
Spark Streaming是將流式計(jì)算分解成一系列短小的批處理作業(yè)。這里的批處理引擎是Spark,也就是把Spark Streaming的輸入數(shù)據(jù)按照batch size(如1秒)分成一段一段的數(shù)據(jù),每一段數(shù)據(jù)都轉(zhuǎn)換成Spark中的RDD,然后將Spark Streaming中對(duì)DStream的Transformation操作變?yōu)獒槍?duì)Spark中對(duì)RDD的Transformation操作,將RDD經(jīng)過操作變成中間結(jié)果保存在內(nèi)存中。整個(gè)流式計(jì)算根據(jù)業(yè)務(wù)的需求可以對(duì)中間的結(jié)果進(jìn)行疊加,或者存儲(chǔ)到外部設(shè)備。下圖顯示了Spark Streaming的整個(gè)流程。
WordCount的例子:
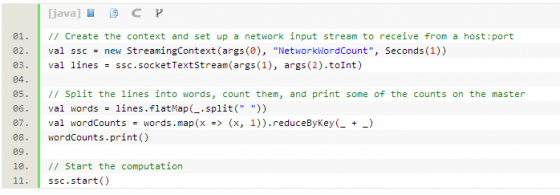
這個(gè)例子使用Scala寫的,一個(gè)簡(jiǎn)單優(yōu)雅的函數(shù)式編程語言,同時(shí)也是基于JVM的后Java類語言。
Storm的設(shè)計(jì)
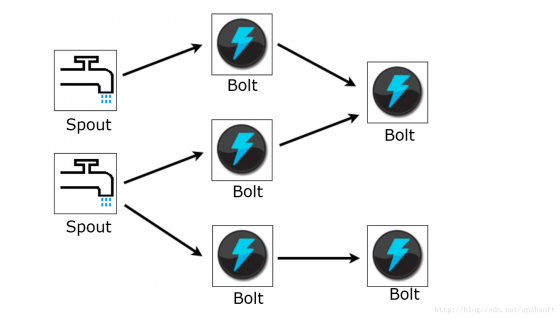
Storm將計(jì)算邏輯成為Topology,其中Spout是Topology的數(shù)據(jù)源,這個(gè)數(shù)據(jù)源可能是文件系統(tǒng)的某個(gè)日志,也可能是MessageQueue的某個(gè)消息隊(duì)列,也有可能是數(shù)據(jù)庫(kù)的某個(gè)表等等;Bolt負(fù)責(zé)數(shù)據(jù)的護(hù)理。Bolt有可能由另外兩個(gè)Bolt的join而來。
而Storm最核心的抽象Streaming就是連接Spout,Bolt以及Bolt與Bolt之間的數(shù)據(jù)流。而數(shù)據(jù)流的組成單位就是Tuple(元組),這個(gè)Tuple可能由多個(gè)Fields構(gòu)成,每個(gè)Field的含義都在Bolt的定義的時(shí)候制定。也就是說,對(duì)于一個(gè)Bolt來說,Tuple的格式是定義好的。
原語設(shè)計(jì)的要點(diǎn)
流式系統(tǒng)的原語設(shè)計(jì),要關(guān)注一下幾點(diǎn):
對(duì)于實(shí)現(xiàn)的邏輯來說,它們都是有向無環(huán)圖的一個(gè)節(jié)點(diǎn),那么如何設(shè)計(jì)它們之間的消息傳遞呢?或者說數(shù)據(jù)如何流動(dòng)的?因?yàn)閷?duì)于分布式系統(tǒng)來說,我們不能假定整個(gè)運(yùn)算都是在同一個(gè)節(jié)點(diǎn)上(事實(shí)上,對(duì)于閉源軟件來說,這是可以的,比如就是滿足一個(gè)特定運(yùn)算下的計(jì)算,計(jì)算平臺(tái)也不需要做的那么通用,那么對(duì)于一個(gè)運(yùn)算邏輯讓他在一個(gè)節(jié)點(diǎn)完成也是可以了,畢竟節(jié)省了調(diào)度和網(wǎng)絡(luò)傳輸?shù)拈_銷)。或者說,對(duì)于一個(gè)通用的計(jì)算平臺(tái)來說,我們不能假定任何事情。
消息傳遞和分發(fā)是取決于系統(tǒng)的具體實(shí)現(xiàn)的。通過對(duì)比Storm和Spark,你就明白我為什么這么說了。
Spark的消息傳遞
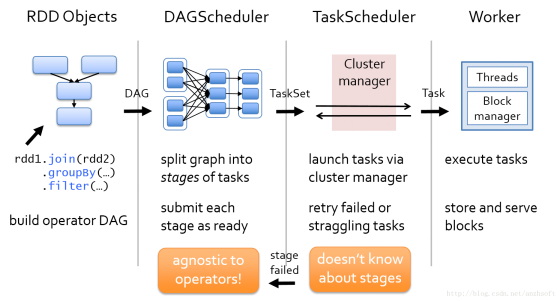
對(duì)于Spark來說,數(shù)據(jù)流是在通過將用戶定義的一系列的RDD轉(zhuǎn)化成DAG圖,然后DAG Scheduler把這個(gè)DAG轉(zhuǎn)化成一個(gè)TaskSet,而這個(gè)TaskSet就可以向集群申請(qǐng)計(jì)算資源,集群把這個(gè)TaskSet部署到Worker中去運(yùn)算了。當(dāng)然了,對(duì)于開發(fā)者來說,他的任務(wù)是定義一些RDD,在RDD上做相應(yīng)的轉(zhuǎn)化動(dòng)作,最后系統(tǒng)會(huì)將這一系列的RDD投放到Spark的集群中去運(yùn)行。
Storm的消息傳遞
對(duì)于Storm來說,他的消息分發(fā)機(jī)制是在定義Topology的時(shí)候就顯式定義好的。也就是說,應(yīng)用程序的開發(fā)者需要清楚的定義各個(gè)Bolts之間的關(guān)系,下游的Bolt是以什么樣的方式獲取上游的Bolt發(fā)出的Tuple。Storm有六種消息分發(fā)模式:
消息傳遞要點(diǎn)
消息隊(duì)列現(xiàn)在是模塊之間通信的非常通用的解決方案了。消息隊(duì)列使得進(jìn)程間的通信可以跨越物理機(jī),這對(duì)于分布式系統(tǒng)尤為重要,畢竟我們不能假定進(jìn)程究竟是部署在同一臺(tái)物理機(jī)上還是部署到不同的物理機(jī)上。RabbitMQ是應(yīng)用比較廣泛的MQ,關(guān)于RabbitMQ可以看我的一個(gè)專欄:RabbitMQ
提到MQ,不得不提的是ZeroMQ。ZeroMQ封裝了Socket,引用官方的說法: “ZMQ (以下 ZeroMQ 簡(jiǎn)稱 ZMQ)是一個(gè)簡(jiǎn)單好用的傳輸層,像框架一樣的一個(gè) socket library,他使得 Socket 編程更加簡(jiǎn)單、簡(jiǎn)潔和性能更高。是一個(gè)消息處理隊(duì)列庫(kù),可在多個(gè)線程、內(nèi)核和主機(jī)盒之間彈性伸縮。ZMQ 的明確目標(biāo)是“成為標(biāo)準(zhǔn)網(wǎng)絡(luò)協(xié)議棧的一部分,之后進(jìn)入 Linux 內(nèi)核”。現(xiàn)在還未看到它們的成功。但是,它無疑是極具前景的、并且是人們更加需要的“傳統(tǒng)”BSD 套接字之上的一層封裝。ZMQ 讓編寫高性能網(wǎng)絡(luò)應(yīng)用程序極為簡(jiǎn)單和有趣。”
因此, ZeroMQ不是傳統(tǒng)意義上的MQ。它比較適用于節(jié)點(diǎn)之間和節(jié)點(diǎn)與Master之間的通信。Storm在0.8之前的Worker之間的通信就是通過ZeroMQ。但是為什么0.9就是用Netty替代了ZeroMQ呢?說替代不大合適,只是0.9的默認(rèn)的Worker之間的通信是使用了Netty,ZeroMQ還是支持的。Storm官方認(rèn)為ZeroMQ有以下缺點(diǎn):
當(dāng)然了還有所謂的性能問題,具體可以訪問Netty作者的blog。結(jié)論就是Netty的性能比ZMQ(在默認(rèn)配置下)好兩倍。不知道所謂的ZMQ的默認(rèn)配置是什么。反正我對(duì)這個(gè)結(jié)果挺驚訝。當(dāng)然了,Netty使用Java實(shí)現(xiàn)的確方便了在Worker之間的通信加上授權(quán)和認(rèn)證機(jī)制。這個(gè)使用ZMQ的確是不太好做。
HA是分布式系統(tǒng)的必要屬性。如果沒有HA,其實(shí)系統(tǒng)是不可用的。那么如果實(shí)現(xiàn)HA?對(duì)于Storm來說,它認(rèn)為Master節(jié)點(diǎn)Nimbus是無狀態(tài)的,無狀態(tài)意味著可以快速恢復(fù),因此Nimbus并沒有實(shí)現(xiàn)HA(不知道以后的Nimbus是否會(huì)實(shí)現(xiàn)HA,實(shí)際上使用ZooKeeper實(shí)現(xiàn)節(jié)點(diǎn)的HA是開源領(lǐng)域的通用做法)。為什么說Nimbus是無狀態(tài)的呢?因?yàn)榧核械脑獢?shù)據(jù)都保存到了ZooKeeper(ZK)中。Nimbus定時(shí)從ZK獲取信息,并且通過向ZK寫信息來控制Worker。Worker也是通過從ZK中獲取信息,通過這種方式,Worker執(zhí)行從Nimbus傳遞過來的命令。
Storm的這種使用ZK的方式還是很值得借鑒的。
Spark是如何實(shí)現(xiàn)HA的?我的另外一篇文章分析過Spark的Master是怎么實(shí)現(xiàn)HA的:Spark技術(shù)內(nèi)幕:Master基于ZooKeeper的High Availability(HA)源碼實(shí)現(xiàn) 。
也是通過ZK的leader 選舉實(shí)現(xiàn)的。Spark使用了百行代碼的級(jí)別實(shí)現(xiàn)了Master的HA,由此可見ZK的功力。
除了這些Master的HA,還有每個(gè)Worker的HA。或者說Worker的HA說法不太準(zhǔn)確,因此對(duì)于集群里的工作節(jié)點(diǎn)來說,它可以非常容易失敗的。這里的HA可以說是如何讓W(xué)orker失敗后快速重啟,重新提供服務(wù)。實(shí)現(xiàn)方式也可以由很多種。一個(gè)簡(jiǎn)單的方法就是使用一個(gè)容器(Container)啟動(dòng)Worker并且監(jiān)控Worker的狀態(tài),如果Worker異常退出,那么就重新啟動(dòng)它。這個(gè)方法很簡(jiǎn)單也很有效。
如果是節(jié)點(diǎn)宕機(jī)呢?上述方法肯定是不能用的。這種情況下Master會(huì)檢測(cè)到Worker的心跳超時(shí),那么就會(huì)從資源池中把這個(gè)節(jié)點(diǎn)刪除。回到正題,宕機(jī)后的節(jié)點(diǎn)重啟涉及到了運(yùn)維方面的知識(shí)。對(duì)于一個(gè)集群來說,硬件宕機(jī)這種情況應(yīng)該需要統(tǒng)一的管理,也就是集群也可以由一個(gè)Master,維持每個(gè)節(jié)點(diǎn)的心跳來確定硬件的狀態(tài)。如果節(jié)點(diǎn)宕機(jī),那么集群首先是重啟它。如果啟動(dòng)失敗可能會(huì)通過電話或者短信或者郵件通知運(yùn)維人員。因此運(yùn)維人員為了保證集群的高可用性付出了很多的努力,尤其是大型互聯(lián)網(wǎng)公司的運(yùn)維人員,非常值得點(diǎn)贊。當(dāng)然了這個(gè)已經(jīng)不是Storm或者Spark所能涵蓋的了。
其實(shí),數(shù)據(jù)不丟失有時(shí)候和處理速度是矛盾的。為了數(shù)據(jù)不丟失就要進(jìn)行數(shù)據(jù)持久化,數(shù)據(jù)持久化意味著要寫硬盤,在固態(tài)硬盤還沒有成為標(biāo)配的今天,硬盤的IO速度永遠(yuǎn)是系統(tǒng)的痛點(diǎn)。當(dāng)然了可以在另外節(jié)點(diǎn)的內(nèi)存上進(jìn)行備份,但是這涉及到了集群的兩個(gè)稀缺資源:內(nèi)存和網(wǎng)絡(luò)。如果因?yàn)閭浞荻加昧舜罅康木W(wǎng)絡(luò)帶寬的話,那必將影響系統(tǒng)的性能,吞吐量。
當(dāng)然了,可以使用日志的方式。但是日志的話對(duì)于錯(cuò)誤恢復(fù)的時(shí)間又是不太能接受的。流式計(jì)算系統(tǒng)的特點(diǎn)就是要快,如果錯(cuò)誤恢復(fù)時(shí)間太長(zhǎng),那么可能不如直接replay來的快,而且系統(tǒng)設(shè)計(jì)還更為簡(jiǎn)單。
其實(shí)如果不是為了追求100%的數(shù)據(jù)丟失,可以使用checkpoint的機(jī)制,允許一個(gè)時(shí)間窗口內(nèi)的數(shù)據(jù)丟失。
回到系統(tǒng)設(shè)計(jì)本身,實(shí)際上流式計(jì)算系統(tǒng)主要是為了離線和近線的機(jī)器學(xué)習(xí)和數(shù)據(jù)挖掘,因此肯定要保證數(shù)據(jù)的處理速度:至少系統(tǒng)可以處理一天的新增數(shù)據(jù),否則數(shù)據(jù)堆積越來越大。因此即使有的數(shù)據(jù)處理丟失了數(shù)據(jù),可以讓源頭重新發(fā)送數(shù)據(jù)。
還有另外一個(gè)話題,就是系統(tǒng)的元數(shù)據(jù)信心如何保存,因?yàn)橄到y(tǒng)的路由信息等需要是全局可見的,需要保存類似的這些數(shù)據(jù)以供集群查詢。當(dāng)然了Master節(jié)點(diǎn)保持了和所有節(jié)點(diǎn)的心跳,它完全可以保存這些數(shù)據(jù),并且在心跳中可以返回這些數(shù)據(jù)。實(shí)際上HDFS的NameNode就是這么做的。HDFS的NN這種設(shè)計(jì)非常合理,為什么這么說?HDFS的元數(shù)據(jù)包含了非常多的數(shù)據(jù):
那么對(duì)于流式計(jì)算系統(tǒng)這種算得上輕量級(jí)的元數(shù)據(jù)來說,Master處理這些元數(shù)據(jù)實(shí)際上要簡(jiǎn)單的多,當(dāng)然了,Master需要實(shí)現(xiàn)服務(wù)的HA和數(shù)據(jù)的HA。這些不是一個(gè)輕松的事情。實(shí)際上,可以采用ZooKeeper來保存系統(tǒng)的元數(shù)據(jù)。ZooKeeper使用一個(gè)目錄樹的結(jié)構(gòu)來保存集群的元數(shù)據(jù)。節(jié)點(diǎn)可以監(jiān)控感興趣的數(shù)據(jù),如果數(shù)據(jù)有變化,那么節(jié)點(diǎn)會(huì)收到通知,然后就保證了系統(tǒng)級(jí)別的數(shù)據(jù)一致性。這點(diǎn)對(duì)于系統(tǒng)比較重要,因?yàn)楣?jié)點(diǎn)都是不穩(wěn)定的,因此系統(tǒng)的其他服務(wù)可能都會(huì)因?yàn)楣?jié)點(diǎn)失效而發(fā)生變化,這些都需要通知相關(guān)的節(jié)點(diǎn)更新器服務(wù)列表,保證了部分節(jié)點(diǎn)的失效并不會(huì)影響系統(tǒng)的整體的服務(wù),從而也就實(shí)現(xiàn)了故障對(duì)于用戶的透明性。
包括Spark和Storm,在國(guó)內(nèi)著名的互聯(lián)網(wǎng)公司比如百度,淘寶和阿里巴巴都有應(yīng)用,但是它究竟貢獻(xiàn)了多少流量是不得而知的。我了解到的是實(shí)際上大部分的流量,尤其是核心流量還是走公司的老架構(gòu)的。著名的博主陳皓在微博上關(guān)于閉源軟件和開源軟件“特點(diǎn)”之爭(zhēng)算是引起了軒然大波,具體討論可以見知乎。之所以引用這個(gè)爭(zhēng)論也是為了切合本小節(jié)的主題:如何與公司已有的生產(chǎn)環(huán)境進(jìn)行融合。
雖然互聯(lián)網(wǎng)公司的產(chǎn)品迭代很快,但是公司的核心算法和架構(gòu)基本上改動(dòng)不會(huì)那么多,因此公司不可能為了推動(dòng)Storm和Spark這種開源產(chǎn)品而進(jìn)行大規(guī)模的重新開發(fā)。只有那么后起的項(xiàng)目,從零開始的項(xiàng)目,比如小規(guī)模的調(diào)研項(xiàng)目才可能用這些產(chǎn)品。當(dāng)然了開源產(chǎn)品首先是一個(gè)通用的平臺(tái),但是通用有可能產(chǎn)生的代價(jià)就是不那么高效,對(duì)于某些特殊地方的不能根據(jù)特殊的應(yīng)用場(chǎng)景進(jìn)行優(yōu)化。如果對(duì)這個(gè)開源平臺(tái)進(jìn)行二次開發(fā),使得性能方面滿足自己的需求,首先不管法務(wù)上的問題,對(duì)于自己私有版本和社區(qū)版本進(jìn)行merge也是個(gè)很大的challenge。就像現(xiàn)在很多公司對(duì)于Linux進(jìn)行了二次裁剪,開發(fā)自己需要的Linux一樣。都需要一些對(duì)于這些架構(gòu)非常熟悉,并且非常熟悉社區(qū)動(dòng)態(tài)的人去做這些事情。而這些在互聯(lián)網(wǎng)公司,基本上是不可能的。因此大部分時(shí)候,都是自己做一個(gè)系統(tǒng),去非常高效切合的去滿足自身的需求。
當(dāng)然了,開源社區(qū)的閃光點(diǎn)也會(huì)影響到閉源產(chǎn)品,閉源產(chǎn)品也會(huì)影響開源產(chǎn)品,這個(gè)相互影響是良性的,可以推動(dòng)技術(shù)向前發(fā)展。
Storm和Spark的設(shè)計(jì),絕對(duì)不是一篇文章所能解決的。它里邊由非常多的哲學(xué)需要我們仔細(xì)去學(xué)習(xí)。它們可以說是我們進(jìn)行系統(tǒng)設(shè)計(jì)的良好的范例。本博客在接下來的半年會(huì)通過Spark的源碼來學(xué)習(xí)Spark的系統(tǒng)架構(gòu)。敬請(qǐng)期待!
原文鏈接: 從Storm和Spark Streaming學(xué)習(xí)流式實(shí)時(shí)分布式計(jì)算系統(tǒng)的設(shè)計(jì)要點(diǎn)(責(zé)編/魏偉)

程序員人生,我編程,我富裕,記住wfuyu網(wǎng),php教程,php學(xué)習(xí),php手冊(cè),CMS模版制作
聲明:本站大部分內(nèi)容是作者原創(chuàng),少部分收集于互聯(lián)網(wǎng)供大家一起學(xué)習(xí),原版權(quán)很多不明,如有侵權(quán)請(qǐng)聯(lián)系本站,謝謝!
粵ICP備14040726號(hào)-1?? 2015-2020 程序員人生 版權(quán)所有


